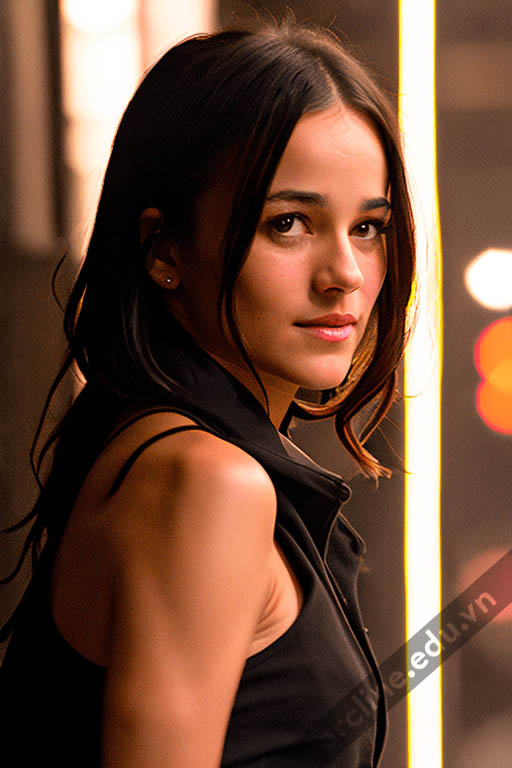Một trong những ứng dụng phổ biến nhất của Stable Diffusion là tạo ra hình ảnh con người rất thực. Chúng có thể trông thực đến mức giống như chụp từ máy ảnh. Trong bài viết này, bạn sẽ tìm hiểu về cơ chế tạo ra những hình ảnh chân dung theo phong cách chụp ảnh. Bạn sẽ được học về các yếu tố như gợi ý, model, và upscalers để tạo ra hình ảnh con người thực tế.
Phần mềm
Chúng tôi sẽ sử dụng giao diện người dùng (GUI) của AUTOMATIC1111 Stable Diffusion để tạo hình ảnh con người thực tế. Bạn có thể sử dụng giao diện này trên Windows, Mac hoặc Google Colab.
Gợi ý (Prompts)
Trong phần này, bạn sẽ học cách xây dựng một prompt chất lượng cao cho phong cách chụp ảnh thực tế từng bước một.
Hãy bắt đầu với một prompt đơn giản về một người phụ nữ đang ngồi ngoài một nhà hàng. Chúng ta sẽ sử dụng v1.5 base model.
Gợi ý:
Ảnh của cô gái trẻ, tóc nổi bật, đang ngồi ngoài nhà hàng, mặc váy
Model: Stable Diffusion v1.5
Phương pháp lấy mẫu (Sampling method): DPM++ 2M Karras
Số bước lấy mẫu (Sampling steps:) 20
CFG Scale: 7
Kích thước: 512×768
Rõ ràng là kết quả không như mong đợi…
Gợi ý phủ định (Negative prompt)
Hãy thêm một negative prompt. Negative prompt này khá tối giản. Mục đích của nó là tạo ra cấu trúc giống con người hơn và tránh các phong cách không thực tế.
Gợi ý phủ định:
Xấu xí, xấu, tồi tệ, không chín chắn, hoạt hình, anime, 3d, tranh vẽ, đen & trắng
Có vẻ như mọi thứ đã có chút cải thiện: Phần thân trên của các người phụ nữ trông tốt hơn.
Nhưng cấu trúc của phần thân dưới vẫn gặp vấn đề. Vẫn còn nhiều chỗ cần cải thiện.
Từ khóa về ánh sáng
Một phần lớn công việc của một nhiếp ảnh gia là thiết lập ánh sáng tốt. Một bức ảnh tốt có ánh sáng thú vị. Điều này cũng áp dụng cho Stable Diffusion. Hãy thêm một số từ khóa về ánh sáng và một từ khóa kiểm soát góc nhìn.
rim lighting
studio lighting
looking at the camera
Gợi ý:
Ảnh của cô gái trẻ, tóc nổi bật, đang ngồi ngoài nhà hàng, mặc váy, ánh sáng rim, ánh sáng studio, nhìn vào máy ảnh
Gợi ý phủ định:
Xấu xí, xấu, tồi tệ, không chín chắn, hoạt hình, anime, 3d, tranh vẽ, đen & trắng
Những bức ảnh ngay lập tức trở nên thú vị hơn. Bạn có thể nhận thấy cấu trúc không hoàn toàn đúng. Đừng lo lắng. Có nhiều cách để sửa chữa nó. Tôi sẽ nói về điều đó trong phần sau của bài viết.
Từ khóa về máy ảnh
Những từ khóa như dslr, ultra quality, 8K, UHD có thể cải thiện chất lượng của hình ảnh.
Gợi ý:
Ảnh của cô gái trẻ, tóc nổi bật, đang ngồi ngoài nhà hàng, mặc váy, ánh sáng rim, ánh sáng studio, nhìn vào máy ảnh, dslr, chất lượng cực cao, lấy nét sắc nét, tầm nhìn rõ ràng, dof, hạt phim, Fujifilm XT3, hình ảnh rõ nét, 8K UHD
Gợi ý phủ định:
Xấu xí, xấu, tồi tệ, không chín chắn, hoạt hình, anime, 3d, tranh vẽ, đen & trắng
Tôi không thể nói rằng chúng chắc chắn tốt hơn, nhưng chắc chắn không xấu nếu bạn gợi ý thêm.
Chi tiết khuôn mặt
Cuối cùng, một số từ khóa có thể được sử dụng như “gia vị” để mô tả mắt và da. Những từ khóa này nhằm tạo ra một khuôn mặt thực tế hơn.
highly detailed glossy eyes (mắt bóng, chi tiết cao)
high detailed skin (da chi tiết cao)
skin pores (lỗ chân lông)
Một tác dụng phụ của việc sử dụng những từ khóa này là làm cho đối tượng gần máy ảnh hơn.
Kết hợp lại, chúng tôi có prompt cuối cùng như sau.
Gợi ý:
Ảnh của cô gái trẻ, tóc nổi bật, đang ngồi ngoài nhà hàng, mặc váy, ánh sáng rim, ánh sáng studio, nhìn vào máy ảnh, dslr, chất lượng cực cao, lấy nét sắc nét, tầm nhìn rõ ràng, hạt phim, Fujifilm XT3, hình ảnh rõ nét, 8K UHD, mắt bóng chi tiết cao, da chi tiết cao, lỗ chân lông
Gợi ý phủ định:
Xấu xí, xấu, tồi tệ, không chín chắn, hoạt hình, anime, 3d, tranh vẽ, đen & trắng
Bạn có ngạc nhiên khi thấy mô hình cơ sở có thể tạo ra những hình ảnh con người thực tế chất lượng cao như vậy không? Chúng tôi chưa thậm chí sử dụng các mô hình đặc biệt dành cho chụp ảnh thực tế. Nó sẽ còn tốt hơn nữa.
Điều khiển khuôn mặt
Kết hợp hai cái tên (Blending two names)
Bạn muốn tạo ra cùng một khuôn mặt trên nhiều hình ảnh? Một mẹo nhỏ là tận dụng các ngôi sao nổi tiếng. Nét diện mạo của họ là phần dễ nhận biết nhất trên cơ thể. Vì vậy, chúng chắc chắn sẽ thống nhất.
Nhưng chúng ta thường không muốn sử dụng khuôn mặt của họ. Chúng quá nổi bật. Bạn muốn một khuôn mặt mới với một diện mạo nhất định.
Mẹo nhỏ là kết hợp hai khuôn mặt sử dụng lịch trình đề nghị. Cú pháp trong AUTOMATIC1111 là
[người 1: người 2: factor]
factor là một số giữa 0 và 1. Nó chỉ ra tỷ lệ của tổng số bước khi từ khóa chuyển từ người 1 sang người 2. Ví dụ, [Ana de Armas:Emma Watson:0.5] với 20 bước nghĩa là đề nghị sử dụng Ana de Armas trong các bước 1 – 10, và sử dụng Emma Watson trong các bước 11-20.
Bạn chỉ cần đưa nó vào gợi ý như sau.
Gợi ý:
Ảnh của cô gái trẻ, [Ana de Armas:Emma Watson:0.5], tóc nổi bật, đang ngồi ngoài nhà hàng, mặc váy, ánh sáng rim, ánh sáng studio, nhìn vào máy ảnh, dslr, chất lượng cực cao, lấy nét sắc nét, tầm nhìn rõ ràng, hạt phim, Fujifilm XT3, hình ảnh rõ nét, 8K UHD, mắt bóng chi tiết cao, da chi tiết cao, lỗ chân lông
Gợi ý:
Xấu xí, xấu, tồi tệ, không chín chắn, hoạt hình, anime, 3d, tranh vẽ, đen & trắng
[Ana de Armas:Emma Watson:0.5]
[Amber Heard: Emma Watson :0.5]
[Anna Kendrick: Liza Soberano 0.5]
Bằng cách chỉnh sửa cẩn thận yếu tố, bạn có thể điều chỉnh tỷ lệ giữa hai khuôn mặt.
Kết hợp một cái tên (Blending one name)
Bạn có để ý rằng phông nền và cấu trúc đã thay đổi rất nhiều khi sử dụng hai tên? Đó là hiệu ứng liên kết. Hình ảnh của các nữ diễn viên thường liên kết với một số cài đặt nhất định, như lễ trao giải.
Cấu trúc tổng thể được đặt bởi từ khóa đầu tiên vì máy lấy mẫu làm sạch nhiễu nhất trong những bước đầu tiên.
Tận dụng ý tưởng này, chúng ta vẫn có thể sử dụng từ “woman” trong những bước đầu tiên và chỉ chuyển sang tên ngôi sao sau đó. Điều này giữ nguyên cấu trúc trong khi cung cấp khả năng kết hợp một khuôn mặt phổ thông với một ngôi sao.
Gợi ý có thể như sau:
Ảnh của cô gái trẻ [woman:Ana de Armas:0.4], tóc nổi bật, đang ngồi ngoài nhà hàng, mặc váy, ánh sáng rim, ánh sáng studio, nhìn vào máy ảnh, dslr, chất lượng cực cao, lấy nét sắc nét, tầm nhìn rõ ràng, hạt phim, Fujifilm XT3, hình ảnh rõ nét, 8K UHD, mắt bóng chi tiết cao, da chi tiết cao, lỗ chân lông
Gợi ý phủ định có thể giữ nguyên.
Xấu xí, xấu, tồi tệ, không chín chắn, hoạt hình, anime, 3d, tranh vẽ, đen & trắng
[woman: Ana de Armas: 0.4]
[woman: Amber Heard: 0.6]
[woman: emma watson: 0.6]
Sử dụng kỹ thuật này, chúng ta có thể giữ nguyên cấu trúc trong khi kiểm soát khuôn mặt đến một mức độ nào đó.
Vẽ lại khuôn mặt (Inpainting faces)
Inpainting là một kỹ thuật để giữ cả cấu trúc và kiểm soát hoàn toàn khuôn mặt.
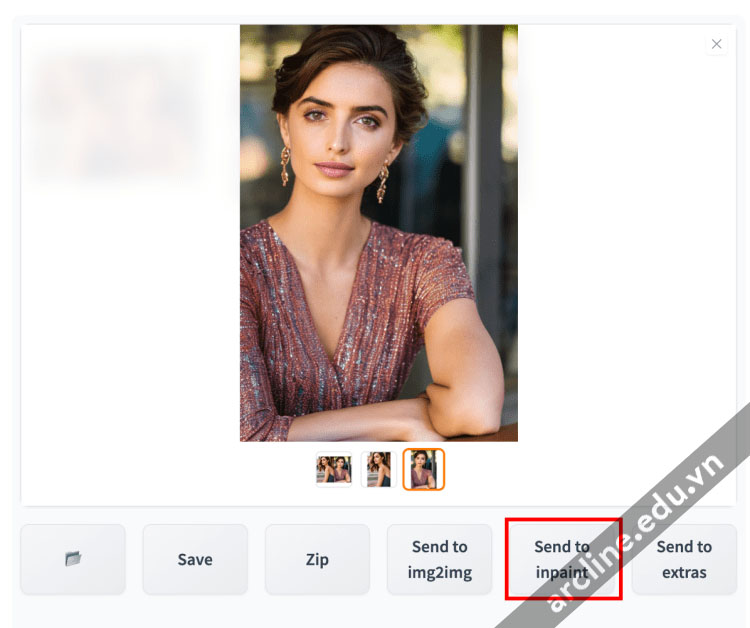
Sau khi tạo hình ảnh trong tab txt2img, nhấp vào Send to inpainting.
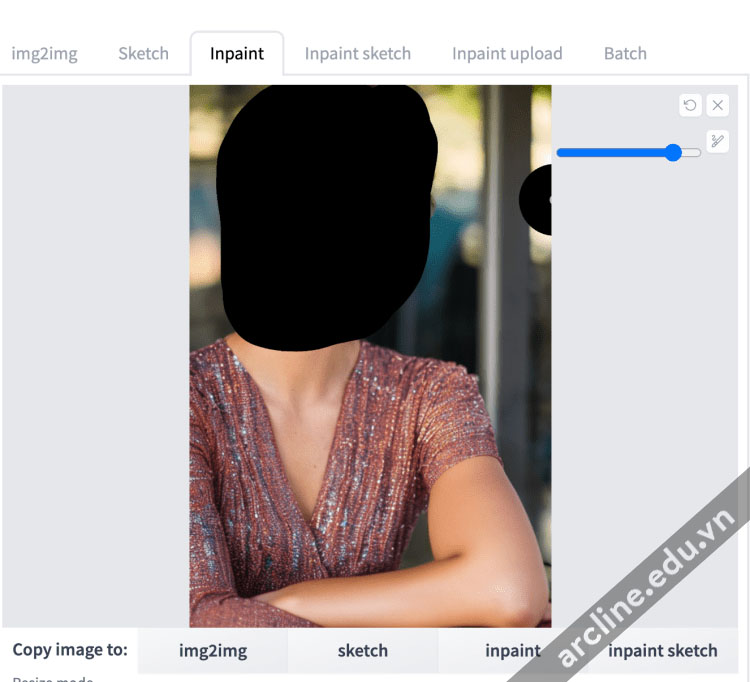
Trong bảng vẽ điều chỉnh, vẽ một mặt nạ che phủ khuôn mặt.
Bây giờ chỉnh sửa đề nghị để bao gồm việc kết hợp hai khuôn mặt. Ví dụ:
Ảnh của cô gái trẻ [Emma Watson: Ana de Armas: 0.4], tóc nổi bật, đang ngồi ngoài nhà hàng, mặc váy, ánh sáng rim, ánh sáng studio, nhìn vào máy ảnh, dslr, chất lượng cực cao, lấy nét sắc nét, tầm nhìn rõ ràng, hạt phim, Fujifilm XT3, hình ảnh rõ nét, 8K UHD, mắt bóng chi tiết cao, da chi tiết cao, lỗ chân lông
Đặt cường độ làm sạch nhiễu (denoising strength) ở 0.75 và kích cỡ mẻ (batch size) ở 8. Nhấn Generate và chọn một cái tốt nhất.
Bạn không cần phải tạo ra những người có vẻ ngoài thực tế với cấu trúc giải phẫu chính xác chỉ trong một lần. Việc tạo lại một phần của hình ảnh là khá dễ dàng.
Hãy cùng đi qua một ví dụ. Hình ảnh con người dưới đây trông khá tốt, ngoại trừ việc cánh tay bị biến dạng.
Để khắc phục, đầu tiên nhấp vào Send to inpaint để gửi hình ảnh và các tham số vào phần “inpainting” của tab “img2img”.
Trong khung vẽ “inpainting” của tab “img2img”, vẽ một mặt nạ trên khu vực gặp vấn đề.
Thiết lập Seed thành -1 (ngẫu nhiên), denoising strength thành 1, và batch size thành 8.
Bạn có thể thử nghiệm với cài đặt “inpaint area” – toàn bức ảnh hoặc chỉ khu vực đã đánh dấu.
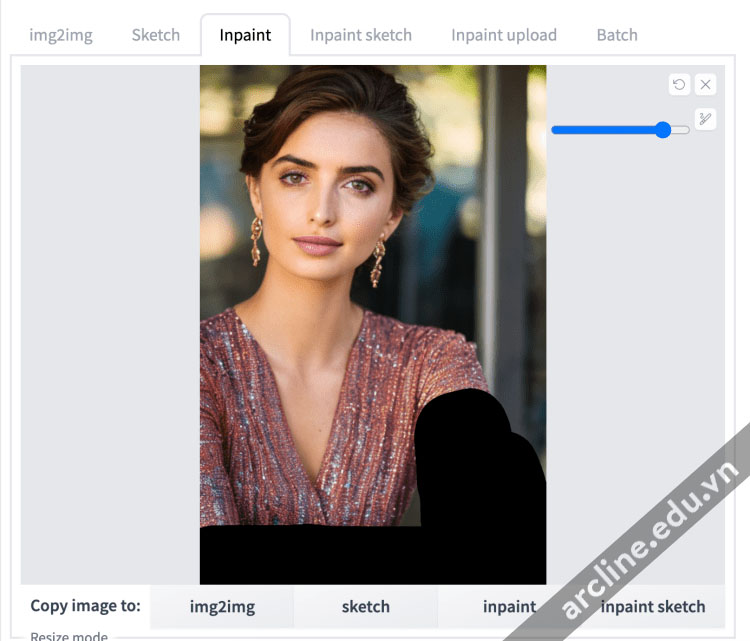
Nhấn Generate.
Sẽ có một số kết quả không như ý muốn. Nhưng bạn sẽ thấy một kết quả tương đối ổn. Nếu không, nhấn Generate một lần nữa.
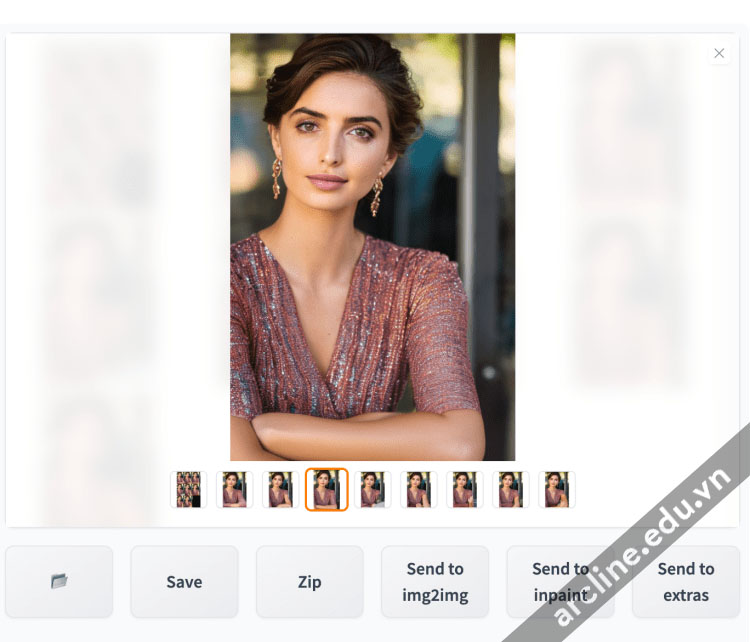
Bạn không cần phải hoàn thiện inpainting chỉ trong một lần. Bạn có thể cải thiện một hình ảnh theo từng lần với inpainting. Khi bạn thấy hình ảnh di chuyển theo hướng đúng, nhấn Send to inpaint.
Bây giờ bạn đang làm việc trên hình ảnh mới. Hãy giảm dần độ mạnh của denoising để giữ lại nội dung của hình ảnh. Dưới đây là một ví dụ về việc thực hiện một vòng inpainting thứ hai. Độ mạnh của denoising đã được thiết lập thành 0.6.
Các mô hình
Cho đến nay, chúng tôi chỉ sử dụng mô hình cơ sở Stable Diffusion v1.5 để tạo ra những người thực tế. Bạn có biết rằng có những mô hình được đào tạo cụ thể để tạo ra hình ảnh thực tế không?
Mọi thứ sẽ chỉ càng tốt hơn khi bạn sử dụng chúng.
Bạn sẽ tìm hiểu về một số mô hình thường được sử dụng.
F222
Hassan blend 1.4
Realistic Vision v2
Chillout Mix
Dreamlike Photoreal
URPM
Tôi sẽ sử dụng cùng một gợi ý:
Hình ảnh của một cô gái trẻ, tóc nổi bật, ngồi bên ngoài nhà hàng, mặc váy, ánh sáng viền, ánh sáng studio, nhìn vào máy ảnh, máy ảnh DSLR, chất lượng cực cao, tập trung sắc nét, độ sắc nét, sâu độ, hạt phim, Fujifilm XT3, rõ nét tinh khiết, 8K UHD, đôi mắt bóng đẹp tinh tế, da chi tiết cao, lỗ chân lông
và gợi ý phủ định:
Hình ảnh bị biến dạng, xấu xí, tồi tệ, chưa trưởng thành, phong cách hoạt hình, anime, 3D, tranh vẽ, đen trắng.
Tôi sẽ đưa ra liên kết tải trực tiếp cho mỗi mô hình. Bạn chỉ cần sao chép và dán liên kết vào trường “Model_from_URL” trong notebook Colab AUTOMATIC1111 của chúng tôi.
Cảnh báo
Hầu hết tất cả chúng đều có khả năng tạo ra hình ảnh khiêu dâm. Sử dụng các thuật ngữ về quần áo như dress trong prompt và nude trong negative prompt để kiềm chế chúng.
Một số mô hình có giấy phép riêng giới hạn hơn. Hãy đọc chúng trước khi sử dụng hoặc tích hợp chúng vào sản phẩm.
Hassan Blend v1.4 được điều chỉnh tinh chỉnh trên một số lượng lớn hình ảnh rõ ràng.
Realistic Vision v2.0
Trang Model
Liên kết tải trực tiếp
https://civitai.com/api/download/models/29460
Realistic Vision v2 là một mô hình toàn diện để tạo ra hình ảnh phong cách nhiếp ảnh. Ngoài việc tạo ra những người thực tế, nó cũng tốt cho động vật và cảnh vật.
Cấu trúc giải phẫu là tuyệt vời, theo kinh nghiệm của tôi.
Chillout Mix
Trang Model
Liên kết tải trực tiếp
https://civitai.com/api/download/models/11745
Chillout Mix là phiên bản Châu Á của F222. Nó được đào tạo để tạo ra hình ảnh con người châu Á.
Dreamlike Photoreal là mô hình phong cách ảnh chung. Các hình ảnh chân dung có xu hướng hơi bị nhuốm màu.
URPM
Trang Model
Liên kết tải trực tiếp
https://civitai.com/api/download/models/15640
URPM là mô hình điều chỉnh tinh chỉnh với các hình ảnh rõ ràng. Cấu trúc giải phẫu thường rất tốt. Hình ảnh tương tự với Realistic Vision v2 nhưng tinh chỉnh hơn một chút.
Sự so sánh
Để cho bạn so sánh trực tiếp các model thực tế, tôi đã sử dụng ControlNet để sửa tư thế. (Chi tiết hơn về điều này sau)
Cùng một gợi ý, gợi ý phủ định và seed được sử dụng.
Stable Diffusion v1.5
F222
Hassan blend 1.4
Realistic Vision v2
Chillout Mix
Dreamlike Photoreal
URPM
Cùng xem rõ hơn:
Stable Diffusion v1.5
F222
Hassan blend 1.4
Realistic Vision v2
Chillout Mix
Dreamlike Photoreal
URPM
LoRA, hypernetwork, textual inversion
Bạn có thể điều chỉnh thêm mô hình bằng cách bổ sung các trình điều khiển mô hình như LoRA, hypernetwork và textual inversions.
Nơi tốt nhất để tìm chúng là civitai.
Phong cách thẩm mỹ Hàn Quốc
Bạn có thể đạt được diện mạo thần tượng Hàn Quốc bằng cách sử dụng embedding (biểu diễn) Ulzzang-6500 với Chillout Mix.
Hình ảnh tối hơn
epi_noiseoffset là một LoRA có thể tạo ra các hình ảnh tối hơn so với bình thường trong Stable Diffusion. Sử dụng các từ khóa tối như “dark studio”, “night”, “dimly lit”, vv.
Gợi ý:
đêm, (dark studio:1.3) hình ảnh của một cô gái trẻ, tóc nổi bật, ngồi bên ngoài nhà hàng, mặc váy, ánh sáng viền, ánh sáng studio, nhìn vào máy ảnh, máy ảnh DSLR, chất lượng cực cao, tập trung sắc nét, độ sắc nét, sâu độ, hạt phim, Fujifilm XT3, rõ nét tinh khiết, 8K UHD, đôi mắt bóng đẹp tinh tế, da chi tiết cao, lỗ chân lông lora:epiNoiseoffset_v2:1
Gợi ý phủ định:
biến dạng, xấu xí, tồi tệ, chưa trưởng thành, phong cách hoạt hình, anime, 3D, tranh vẽ, đen trắng
Các hình ảnh con người dưới đây được tạo ra bằng mô hình URPM.
LoRA của ngôi sao
Có một số lượng lớn các mô hình LoRA do người hâm mộ tạo ra để tưởng nhớ các nghệ sĩ yêu thích của họ.
Alizée Jacotey
Natalie Portman「LoRa」
Trang phục
LoRA trang phục Hán Trung Quốc này (được áp dụng trên Chillout Mix) rất xuất sắc trong việc tạo ra những bộ trang phục Hán truyền thống đẹp đẽ.
ControlNet đã trở thành tiêu chuẩn chung để điều chỉnh tư thế người và cách cắt chân dung.
Nhưng làm thế nào để có được hình ảnh tham chiếu? Một cách dễ dàng là tìm các trang web ảnh miễn phí như Unsplash. Tìm kiếm với các từ khóa như nam, nữ, đứng, ngồi, vv. Bạn sẽ tìm thấy một hình ảnh với cấu trúc đúng.
Sử dụng openpose ControlNet. Xem bài viết ControlNet để biết thêm chi tiết.
ControlNet cho hai người
Mà không có ControlNet, thì việc điều chỉnh cấu trúc và tư thế của hai hoặc nhiều người trong một cảnh quay gần như không thể. Bây giờ, bạn chỉ cần tìm hình ảnh tham khảo và bạn có thể thực hiện.
Hình ảnh tham khảo
Chillout Mix
Realistic Vision v2
Trình tạo độ phân giải cao (Upscaler)
Độ phân giải tự nhiên của mô hình SD v1 là 512×512 pixel. Để tránh các vấn đề như tạo ra nhân vật trùng lặp, bạn nên đặt ít nhất một mặt thành 512 pixel.
Kết quả là hình ảnh có thể nhỏ quá cho việc sử dụng sau này.
Bạn có thể sử dụng các trình tạo độ phân giải trí tuệ nhân tạo để làm to hình ảnh mà không lo lắng về việc nó bị mờ đi. Chúng có khả năng tạo nội dung để điền vào chi tiết khi bạn làm to hình ảnh.
Mẹo khi sử dụng trình tạo độ phân giải cao cho ảnh thực tế
Một số điểm về trình tạo độ phân giải cao cho hình ảnh thực tế:
Hầu hết các trình tạo độ phân giải cao sẽ thay đổi hình ảnh.
Thử nghiệm áp dụng hai trình tạo độ phân giải cao. Trình đầu tiên là một trình tạo độ phân giải truyền thống như Lanczos. Trình thứ hai là một trình tạo độ phân giải trí tuệ nhân tạo như R-ESRGAN. Bạn nên áp dụng ít nhất là lượng nhỏ nhất của trình tạo độ phân giải trí tuệ nhân tạo có thể.
Tương tự cho khôi phục khuôn mặt. Áp dụng nó với độ mạnh tối thiểu có thể để tránh xuất hiện hiện tượng nghệ thuật. Áp dụng ít nhất mức có thể để được thông qua.
Bạn có thể làm to hơn những gì bạn cần. Sau đó làm nhỏ nó lại. Như vậy, bạn có thể chấp nhận hình ảnh được làm to hơi mờ đi một chút.
Không có trình tạo độ phân giải cao với ControlNet
Bạn có thể thử nghiệm tạo ra hình ảnh với độ phân giải cuối cùng khi sử dụng ControlNet. Điều này có thể hoạt động bởi vì ControlNet sửa các tư thế và ngăn ngừa các vấn đề thông thường như tạo ra hai đầu hoặc cơ thể trùng lặp.
Hãy thử đặt kích thước hình ảnh là, ví dụ, 1200×800. Có cơ hội bạn có thể thử nghiệm việc sử dụng trình tạo độ phân giải cao!
Chuyển đổi hình ảnh theo hình ảnh sau khi phóng to
Để loại bỏ hiện tượng nghệ thuật được giới thiệu bởi trình tạo độ phân giải cao, bạn có thể thực hiện chuyển đổi hình ảnh theo hình ảnh với độ mạnh giảm tiếng ồn thấp (ví dụ: 0.1 đến 0.3), trong khi giữ nguyên prompt.
Mẹo này giúp mô hình tạo ra chi tiết phù hợp với phong cách của mô hình mà không thay đổi hình ảnh quá nhiều.
Nhược điểm là hình ảnh sẽ bị sửa đổi một chút, phụ thuộc vào denoising strength mà bạn sử dụng.
Cải thiện chi tiết
Để cải thiện chi tiết và làm to cùng một lúc, sử dụng ControlNet Tile upscale.
Tóm tắt
Dưới đây là một số điểm nhấn.
1. Bắt đầu với prompt cơ bản và negative prompt ở đầu phần Models. Bạn có thể tùy chỉnh hình ảnh bằng cách thay đổi:
Dân tộc – người Mỹ gốc Phi, người Mỹ gốc Latino, người Nga, người châu Âu…
Kiểu tóc – dài, ngắn, đuôi ngựa, tóc bím…
Trang phục – váy, áo phông, quần jeans, áo khoác. Hãy truy cập vào trang web của cửa hàng quần áo yêu thích và lấy ý tưởng về các từ khóa.
Hoạt động – họ đang làm gì
Môi trường xung quanh – đường phố đông đúc, trong nhà, trên bãi biển…
2. Chọn một mô hình
F222 hoặc Realistic Vision v2 cho hình ảnh thực tế và cân đối.
Hassan Blend v1.4 hoặc URPM cho một cái nhìn hoàn thiện hơn.
Chillout Mix cho người châu Á.
SD 1.5 nếu bạn muốn thể hiện kỹ năng tạo prompt xuất sắc của mình…
3. Thêm vào một LoRA, textual inversion hoặc hypernetwork để điều chỉnh hiệu ứng mong muốn.
4. Hướng đến sự cân đối trong cách bố trí. Đừng ngại sử dụng nhiều lượt inpainting để sửa các khuyết điểm hoặc tái tạo khuôn mặt.
5. Sử dụng ControlNet với một bức ảnh chụp sẵn để đạt được tư thế và bố cục tốt.
6. Cẩn thận khi sử dụng trình tạo độ phân giải cao.
Bộ sưu tập
Sau đây là bộ sưu tập về hình ảnh con người thực tế…