
Mô hình Stable Diffusion là một mô hình học sâu. Chúng ta sẽ đào sâu để hiểu cách nó hoạt động bên trong bài viết sau.
Tại sao bạn cần biết? Ngoài việc là một chủ đề hấp dẫn riêng biệt, việc hiểu về cơ chế bên trong sẽ giúp bạn trở thành một nghệ sĩ tốt hơn. Bạn có thể sử dụng công cụ một cách chính xác để đạt được kết quả với độ chính xác cao hơn.
Làm thế nào text-to-image khác biệt so với image-to-image? Giá trị CFG là gì? Sức mạnh giảm nhiễu là gì? Các câu trả lời sẽ có trong bài viết này.
Hãy cùng bắt đầu.
Stable Diffusion có thể làm gì?
Trong dạng đơn giản nhất, mô hình Stable Diffusion là một mô hình text-to-image. Đưa cho nó một lời nhắc văn bản. Nó sẽ trả về một hình ảnh phù hợp với văn bản.
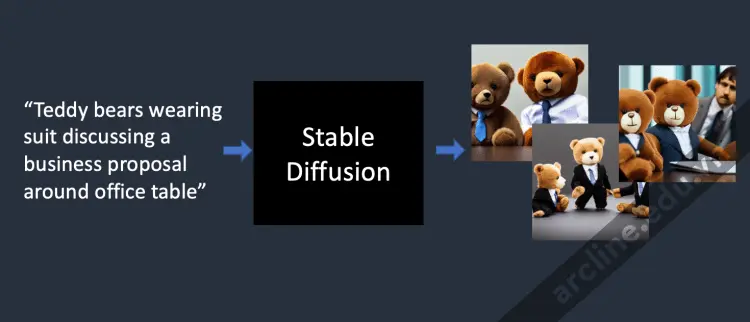
Stable Diffusion biến các đề mục văn bản thành hình ảnh.
Mô hình diffusion
Mô hình Stable Diffusion thuộc loại mô hình học sâu được gọi là mô hình diffusion. Chúng là các mô hình sinh tạo, có nghĩa là chúng được thiết kế để tạo ra dữ liệu mới tương tự những gì chúng đã thấy trong quá trình huấn luyện. Trong trường hợp của Stable Diffusion, dữ liệu là hình ảnh.
Tại sao nó được gọi là mô hình diffusion? Bởi vì toán học của nó trông rất giống sự diffusion trong vật lý. Chúng ta hãy đi qua ý tưởng.
Hãy tưởng tượng tôi đã huấn luyện một mô hình diffusion chỉ với hai loại hình ảnh: mèo và chó. Trong hình dưới đây, hai đỉnh bên trái đại diện cho nhóm hình ảnh mèo và chó.
Forward diffusion
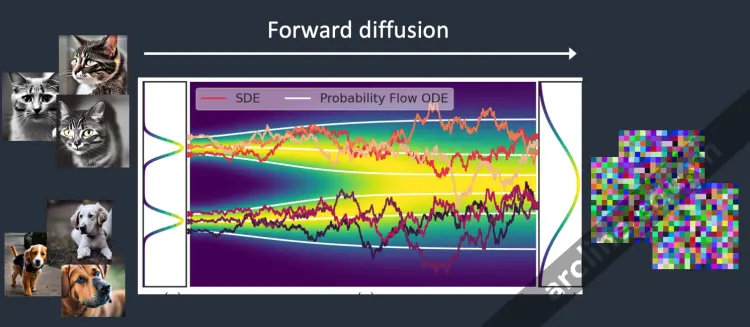
Forward diffusion biến một bức ảnh thành nhiễu.
Quá trình diffusion tiến thêm nhiễu vào một hình ảnh huấn luyện, dần dần biến nó thành một hình ảnh nhiễu không đặc trưng. Quá trình tiến sẽ biến bất kỳ hình ảnh mèo hoặc chó nào thành một hình ảnh nhiễu. Cuối cùng, bạn sẽ không thể nói được liệu chúng ban đầu là một con chó hay con mèo. (Điều này quan trọng)
Đó giống như một giọt mực rơi vào một ly nước. Giọt mực lan tỏa trong nước. Sau vài phút, nó phân bố ngẫu nhiên trong toàn bộ nước. Bạn không còn thể nói liệu nó ban đầu rơi vào trung tâm hay gần viền.
Dưới đây là một ví dụ về một hình ảnh trải qua quá trình diffusion tiến. Hình ảnh mèo biến thành nhiễu ngẫu nhiên.

Forward diffusion của hình ảnh mèo
Reverse diffusion
Giờ đến phần thú vị. Điều gì sẽ xảy ra nếu chúng ta có thể ngược lại quá trình diffusion? Giống như chơi video ngược lại. Đi ngược thời gian. Chúng ta sẽ thấy giọt mực ban đầu được thêm vào ở đâu.
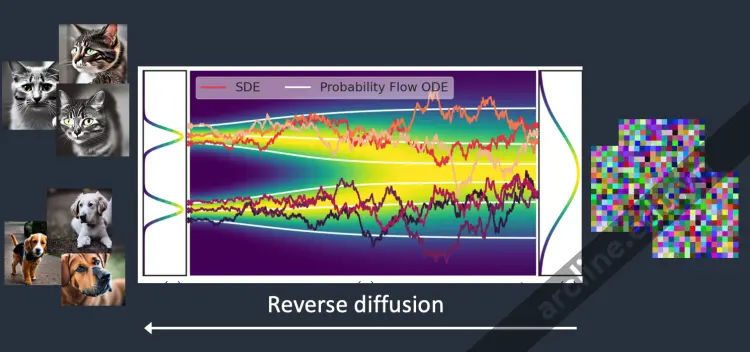
Reverse diffusion khôi phục lại một bức ảnh
Bắt đầu từ một hình ảnh nhiễu, không có ý nghĩa, reverse diffusion khôi phục lại một hình ảnh mèo HOẶC chó. Đây là ý tưởng chính.
Kỹ thuật, mỗi quá trình diffusion có hai phần: (1) sự dịch chuyển và (2) chuyển động ngẫu nhiên. Quá trình reverse diffusion dịch chuyển về hướng hình ảnh mèo HOẶC chó nhưng không có gì ở giữa. Đó là lý do tại sao kết quả có thể là một con mèo hoặc một con chó.
Xem thêm: Stable Diffusion WebUI AUTOMATIC1111: Tất cả những gì bạn cần biết
Quá trình huấn luyện được thực hiện như thế nào
Ý tưởng của reverse diffusion không thể không được xem là thông minh và thanh lịch. Nhưng câu hỏi đáng triệu đô là, “Làm thế nào nó có thể thực hiện được?”
Để ngược lại quá trình diffusion, chúng ta cần biết bao nhiêu nhiễu được thêm vào hình ảnh. Câu trả lời là huấn luyện một mô hình mạng thần kinh để dự đoán nhiễu được thêm vào. Nó được gọi là bộ dự đoán nhiễu trong Stable Diffusion. Đó là một mô hình U-Net. Quá trình huấn luyện diễn ra như sau.
- Chọn một hình ảnh huấn luyện, chẳng hạn như một bức ảnh của một con mèo.
- Tạo ra một hình ảnh nhiễu ngẫu nhiên.
- Làm hỏng hình ảnh huấn luyện bằng cách thêm hình ảnh nhiễu này một số bước nhất định.
- Dạy bộ dự đoán nhiễu cho chúng ta biết bao nhiêu nhiễu đã được thêm vào. Điều này được thực hiện bằng cách điều chỉnh trọng số của nó và cho nó xem câu trả lời đúng.
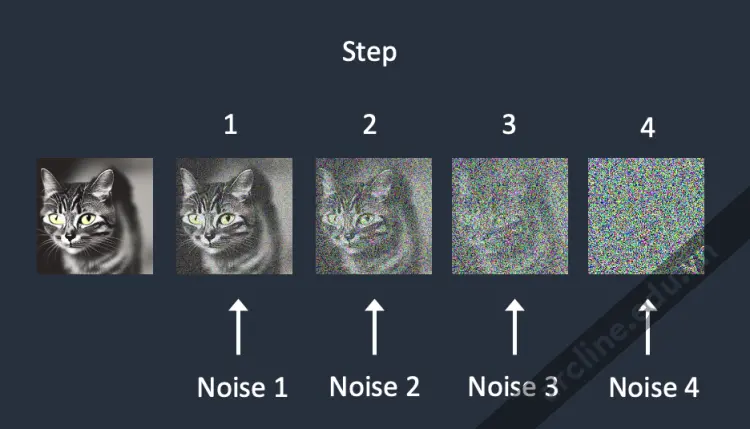
Nhiễu được thêm vào tuần tự ở mỗi bước. Bộ dự đoán nhiễu ước tính tổng nhiễu đã thêm vào cho mỗi bước.
Sau quá trình huấn luyện, chúng ta có một bộ dự đoán nhiễu có khả năng ước tính nhiễu được thêm vào hình ảnh.
Reverse diffusion
Bây giờ chúng ta có bộ dự đoán nhiễu. Làm thế nào để sử dụng nó?
Trước tiên, chúng ta tạo ra một hình ảnh hoàn toàn ngẫu nhiên và yêu cầu bộ dự đoán nhiễu cho chúng ta biết về nhiễu. Sau đó, chúng ta trừ bớt nhiễu ước tính này từ hình ảnh gốc. Lặp lại quá trình này vài lần. Bạn sẽ có một bức ảnh của một con mèo hoặc một con chó.
Reverse diffusion hoạt động bằng cách liên tục trừ nhiễu được dự đoán ra khỏi hình ảnh.
Bạn có thể nhận thấy chúng ta không có khả năng kiểm soát việc tạo ra hình ảnh mèo hoặc chó. Chúng ta sẽ giải quyết vấn đề này khi chúng ta nói về điều kiện. Hiện tại, việc tạo hình ảnh là không được điều kiện.
Mô hình Stable Diffusion
Bây giờ tôi cần nói cho bạn một số tin tức không tốt: Những gì chúng ta vừa nói không phải là cách mô hình Stable Diffusion hoạt động! Lý do là quá trình diffusion ở trên là trong không gian hình ảnh. Nó tính toán rất, rất chậm. Bạn sẽ không thể chạy trên bất kỳ GPU đơn lẻ nào, chưa kể đến GPU tệ hại trên laptop của bạn.
Không gian hình ảnh là rất lớn. Hãy nghĩ về nó: một hình ảnh 512×512 với ba kênh màu (đỏ, xanh lá cây và xanh da trời) là một không gian 786,432 chiều! (Bạn cần chỉ định nhiều giá trị đến vậy cho MỘT hình ảnh.)
Các mô hình diffusion như Imagen của Google và DALL-E của Open AI ở trong không gian pixel. Họ đã sử dụng một số thủ thuật để làm cho mô hình nhanh hơn nhưng vẫn chưa đủ.
Mô hình diffusion tiềm ẩn
Stable Diffusion được thiết kế để giải quyết vấn đề về tốc độ. Dưới đây là cách hoạt động.
Stable Diffusion là một mô hình diffusion tiềm ẩn. Thay vì hoạt động trong không gian hình ảnh có số chiều cao, nó trước tiên nén hình ảnh thành không gian tiềm ẩn. Không gian tiềm ẩn nhỏ hơn 48 lần nên nó thuận lợi trong việc tính toán ít số hơn rất nhiều. Đó là lý do tại sao nó nhanh hơn rất nhiều.
Variational Autoencoder
Nó được thực hiện bằng một kỹ thuật gọi là mạng autoencoder biến phân. Vâng, đó chính xác là những gì các tập tin VAE là, nhưng tôi sẽ làm cho nó rõ ràng hơn sau.
Mạng thần kinh Variational Autoencoder (VAE) có hai phần: (1) một bộ mã hoá và (2) một bộ giải mã. Bộ mã hoá nén một hình ảnh thành một biểu diễn chiều thấp hơn trong không gian tiềm ẩn. Bộ giải mã khôi phục lại hình ảnh từ không gian tiềm ẩn.
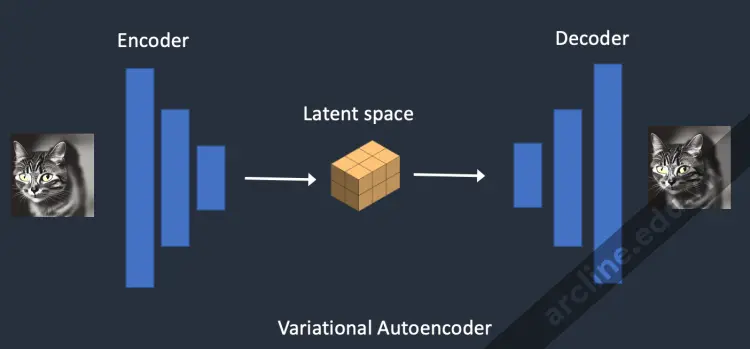
Variational Autoencoder biến đổi hình ảnh vào và ra khỏi không gian tiềm ẩn.
Không gian tiềm ẩn của mô hình Stable Diffusion là 4x64x64, nhỏ hơn 48 lần so với không gian pixel hình ảnh. Tất cả quá trình diffusion tiến về phía trước và ngược lại mà chúng ta đã nói đều được thực hiện trong không gian tiềm ẩn.
Vì vậy, trong quá trình huấn luyện, thay vì tạo ra một hình ảnh nhiễu, nó tạo ra một ma trận tensor ngẫu nhiên trong không gian tiềm ẩn (nhiễu tiềm). Thay vì làm hỏng một hình ảnh bằng tiếng ồn, nó làm hỏng biểu diễn của hình ảnh trong không gian tiềm ẩn bằng nhiễu tiềm. Lý do là nó nhanh hơn rất nhiều vì không gian tiềm ẩn nhỏ hơn.
Độ phân giải hình ảnh
Độ phân giải hình ảnh được phản ánh trong kích thước của tensor hình ảnh tiềm ẩn. Kích thước của hình ảnh tiềm ẩn là 4x64x64 cho hình ảnh 512×512. Đối với hình ảnh chân dung 768×512, nó là 4x96x64. Đó là lý do tại sao nó mất thời gian và VRAM hơn để tạo ra một hình ảnh lớn hơn.
Vì Stable Diffusion v1 đã được điều chỉnh trên hình ảnh 512×512, việc tạo ra hình ảnh lớn hơn 512×512 có thể dẫn đến việc xuất hiện các đối tượng trùng lặp, ví dụ: hai cái đầu khét tiếng. Nếu bạn phải làm điều này, hãy giữ ít nhất một bên là 512 pixel và sử dụng một công cụ tăng cường trí tuệ nhân tạo cho độ phân giải cao.
Tại sao không gian tiềm ẩn có thể?
Bạn có thể tự hỏi tại sao VAE có thể nén một hình ảnh vào không gian tiềm ẩn nhỏ hơn mà không mất thông tin. Lý do là, không ngạc nhiên, hình ảnh tự nhiên không phải là ngẫu nhiên. Chúng có tính đều đặn cao: Khuôn mặt tuân theo mối quan hệ không gian cụ thể giữa mắt, mũi, má và miệng. Một con chó có 4 chân và có hình dáng cụ thể.
Nói cách khác, sự nhiều chiều cao của hình ảnh là giả tạo. Hình ảnh tự nhiên có thể dễ dàng nén vào không gian tiềm ẩn nhỏ hơn mà không mất bất kỳ thông tin nào. Đây được gọi là giả thuyết mani trong học máy.
Reverse diffusion trong không gian tiềm ẩn
Dưới đây là cách ngược lại quá trình diffusion trong không gian tiềm ẩn hoạt động trong Stable Diffusion.
1. Một ma trận không gian tiềm ẩn ngẫu nhiên được tạo ra.
2. Bộ dự đoán nhiễu ước tính nhiễu của ma trận tiềm ẩn.
3. Nhiễu ước tính sau đó được trừ đi từ ma trận tiềm ẩn.
4. Bước 2 và 3 được lặp lại đến số bước mẫu cụ thể.
5. Bộ giải mã của VAE chuyển đổi ma trận tiềm ẩn thành hình ảnh cuối cùng.
Tập tin VAE là gì?
Tập tin VAE được sử dụng trong Stable Diffusion v1 để cải thiện mắt và khuôn mặt. Chúng là bộ giải mã của autoencoder chúng ta vừa nói đến. Bằng cách điều chỉnh lại bộ giải mã, mô hình có thể vẽ chi tiết tốt hơn.
Bạn có thể nhận ra điều tôi đã đề cập trước đó không hoàn toàn chính xác. Việc nén hình ảnh vào không gian tiềm ẩn thực sự mất thông tin vì VAE gốc không khôi phục lại các chi tiết tốt. Thay vào đó, bộ giải mã VAE chịu trách nhiệm vẽ chi tiết tốt.
Conditioning
Sự hiểu biết của chúng ta vẫn còn thiếu sót: Làm thế nào câu hỏi về đoạn văn ghi nhập vào hình ảnh? Mà không có nó, Stable Diffusion không phải là một mô hình chuyển từ văn bản sang hình ảnh. Bạn sẽ chỉ nhận được một bức ảnh về một con mèo hoặc một con chó mà không có cách nào để kiểm soát nó.
Đây là nơi mà sự điều kiện xuất hiện. Mục đích của việc điều kiện là để định hướng bộ dự đoán nhiễu sao cho nhiễu dự đoán sẽ cho chúng ta những gì chúng ta muốn sau khi trừ đi khỏi hình ảnh.
Điều kiện văn bản (text-to-image)
Dưới đây là một cái nhìn tổng quan về cách đoạn văn ghi nhập được xử lý và đưa vào bộ dự đoán nhiễu. Trình mã hóa đầu tiên chuyển đổi mỗi từ trong đoạn văn ghi nhập thành một số gọi là mã thông báo. Sau đó, mỗi mã thông báo được chuyển đổi thành một vector 768 giá trị gọi là nhúng. (Vâng, đây chính là nhúng bạn đã sử dụng trong AUTOMATIC1111) Các nhúng sau đó được xử lý bởi bộ biến đổi văn bản và sẵn sàng được tiêu thụ bởi bộ dự đoán nhiễu.
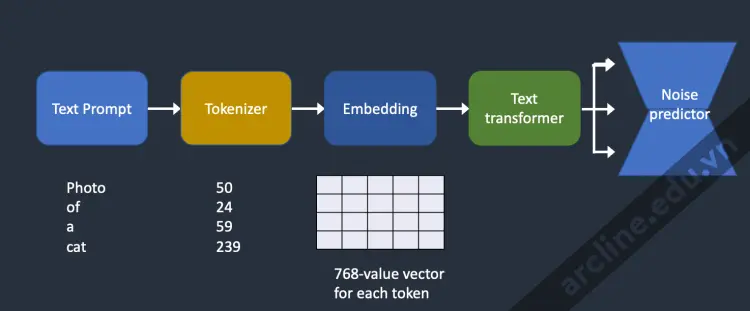
Cách mà yêu cầu văn bản được xử lý và đưa vào bộ dự đoán nhiễu để điều khiển quá trình tạo hình ảnh.
Trình mã hóa (Tokenizer)
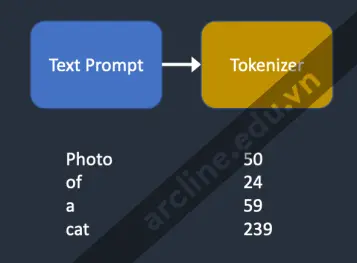
Tokenizer
Đoạn văn ghi nhập đầu tiên được mã hóa bởi một trình mã hóa CLIP. CLIP là một mô hình học sâu được phát triển bởi Open AI để tạo ra mô tả văn bản của bất kỳ hình ảnh nào. Stable Diffusion v1 sử dụng trình mã hóa CLIP.
Mã hóa mã thông báo là cách máy tính hiểu từ. Chúng ta, con người, có thể đọc từ, nhưng máy tính chỉ có thể đọc số. Đó là lý do tại sao các từ trong đoạn văn ghi nhập đầu tiên được chuyển đổi thành số.
Một trình mã hóa chỉ có thể mã hóa các từ nó đã thấy trong quá trình huấn luyện. Ví dụ, trong mô hình CLIP có “dream” và “beach”, nhưng không có “dreambeach”. Trình mã hóa sẽ chia tách từ “dreambeach” thành hai mã thông báo “dream” và “beach”. Vì vậy, một từ không luôn có nghĩa là một mã thông báo!
Một điểm khác cần lưu ý là ký tự dấu cách cũng là một phần của mã thông báo. Trong trường hợp trên, cụm từ “dream beach” tạo ra hai mã thông báo “dream” và “[space]beach”. Những mã thông báo này không giống với mã thông báo được tạo ra bởi “dreambeach” là “dream” và “beach” (không có khoảng trắng trước beach).
Mô hình Stable Diffusion bị giới hạn trong việc sử dụng 75 mã thông báo trong một đoạn văn ghi nhập. (Bây giờ bạn biết rằng nó không giống như 75 từ!)
Nhúng (Embedding)
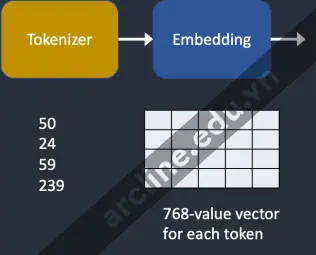
Embedding
Stable diffusion v1 sử dụng mô hình Clip ViT-L/14 của Open AI. Nhúng là một vector 768 giá trị. Mỗi mã thông báo có một vector nhúng riêng biệt của nó. Nhúng được cố định bởi mô hình CLIP, được học trong quá trình huấn luyện.
Tại sao chúng ta cần nhúng? Điều này là do một số từ có mối quan hệ gần nhau với nhau. Chúng tôi muốn tận dụng thông tin này. Ví dụ, nhúng của các từ “man”, “gentleman” và “guy” gần như giống nhau vì chúng có thể được sử dụng thay thế cho nhau. Monet, Manet và Degas đều vẽ theo phong cách ấn tượng nhưng theo cách khác nhau. Các tên có các nhúng gần nhau nhưng không giống nhau.
Đây chính là nhúng chúng ta đã thảo luận về việc kích hoạt một phong cách bằng một từ khóa. Nhúng có thể thực hiện điều kỳ diệu. Các nhà khoa học đã chứng minh rằng việc tìm các nhúng thích hợp có thể kích hoạt các đối tượng và phong cách tùy ý, một kỹ thuật điều chỉnh tinh chỉnh gọi là ngược văn bản.
Cung cấp nhúng cho bộ dự đoán nhiễu
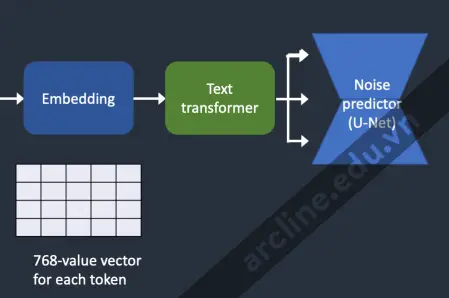
Từ các nhúng đến bộ dự đoán nhiễu.
Nhúng cần phải được xử lý thêm bởi trình biến đổi văn bản trước khi đưa vào bộ dự đoán nhiễu. Trình biến đổi tương tự như một bộ chuyển đổi thông thường cho việc điều kiện. Trong trường hợp này, đầu vào của nó là các vector nhúng văn bản, nhưng nó cũng có thể là một cái gì đó khác như nhãn lớp, hình ảnh và bản đồ độ sâu. Trình biến đổi không chỉ xử lý dữ liệu thêm mà còn cung cấp cơ chế để bao gồm các hình thức điều kiện khác nhau.
Cross-attention
Đầu ra của trình biến đổi văn bản được sử dụng nhiều lần bởi bộ dự đoán nhiễu trong suốt quá trình U-Net. U-Net tiêu thụ nó bằng cơ chế cross-attention. Đó là nơi mà đoạn văn ghi nhập gặp gỡ hình ảnh.
Hãy sử dụng đoạn văn ghi nhập “Một người đàn ông có mắt xanh” làm ví dụ. Stable Diffusion ghép hai từ “xanh” và “mắt” lại với nhau (cross-attention trong đoạn văn ghi nhập) để tạo ra một người đàn ông có mắt xanh nhưng không phải người đàn ông mặc áo xanh. Sau đó, nó sử dụng thông tin này để điều hướng sự lan truyền ngược về các hình ảnh chứa mắt xanh. (Cross-attention giữa đoạn văn ghi nhập và hình ảnh)
Một lưu ý phụ: Hypernetwork, một kỹ thuật để điều chỉnh các mô hình Stable Diffusion, chiếm dụng mạng chéo-quan sát để chèn phong cách. Các mô hình LoRA sửa đổi trọng số của mô-đun chéo-quan sát để thay đổi phong cách. Sự thay đổi mô-đun này một mình có thể điều chỉnh tốt mô hình Stable Diffusion, cho bạn biết mô-đun này quan trọng như thế nào.
Các hình thức điều kiện khác
Đoạn văn ghi nhập văn bản không phải là cách duy nhất mà một mô hình Stable Diffusion có thể được điều kiện.
Cả đoạn văn ghi nhập và hình ảnh độ sâu được sử dụng để điều kiện mô hình độ sâu đến hình ảnh.
ControlNet điều kiện bộ dự đoán nhiễu bằng việc phát hiện đường viền, tư thế người, vv và đạt được kiểm soát tuyệt vời trên việc tạo hình ảnh.
Xem thêm: Stable Diffusion WebUI AUTOMATIC1111: Tất cả những gì bạn cần biết
Stable Diffusion từng bước
Bây giờ bạn đã biết tất cả về cơ chế bên trong của Stable Diffusion, hãy xem xét một số ví dụ về những gì xảy ra bên trong.
Text-to-image
Trong quá trình text-to-image, bạn cung cấp cho Stable Diffusion một đoạn văn ghi nhập văn bản và nó trả lại một bức ảnh.
Bước 1. Stable Diffusion tạo một ma trận ngẫu nhiên hoàn toàn trong không gian tiềm ẩn. Bạn kiểm soát ma trận này bằng cách đặt giá trị hạt của trình tạo số ngẫu nhiên. Nếu bạn đặt hạt vào một giá trị cụ thể, bạn luôn nhận được cùng một ma trận ngẫu nhiên. Đây là hình ảnh của bạn trong không gian tiềm ẩn. Nhưng tất cả đều là nhiễu cho đến bây giờ.

Bước 2. Bộ dự đoán nhiễu U-Net lấy hình ảnh ẩn nhiễu tiềm ẩn và đoạn văn ghi nhập văn bản như đầu vào và dự đoán nhiễu, cũng trong không gian tiềm ẩn (một ma trận 4x64x64).
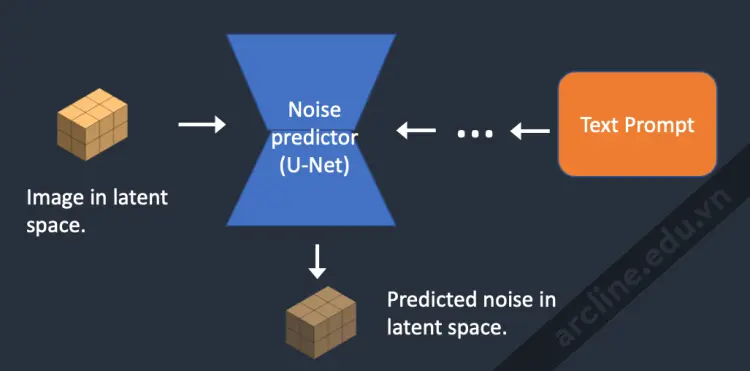
Bước 3. Trừ đi nhiễu tiềm ẩn khỏi hình ảnh tiềm ẩn. Điều này trở thành hình ảnh tiềm ẩn mới của bạn.

Các bước 2 và 3 được lặp lại trong một số bước lấy mẫu nhất định, ví dụ: 20 lần.
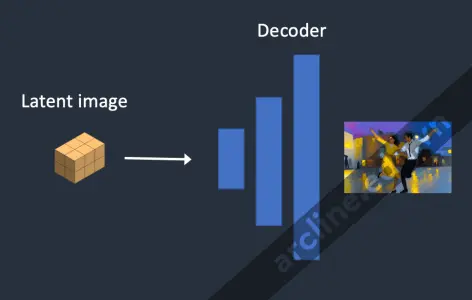
Bước 4. Cuối cùng, bộ giải mã VAE chuyển đổi hình ảnh tiềm ẩn trở lại không gian pixel. Đây là bức ảnh bạn nhận được sau khi chạy Stable Diffusion.
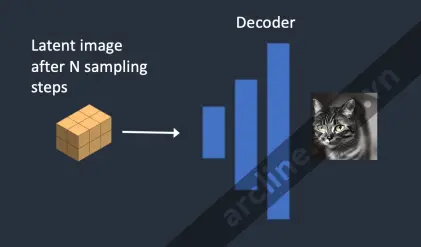
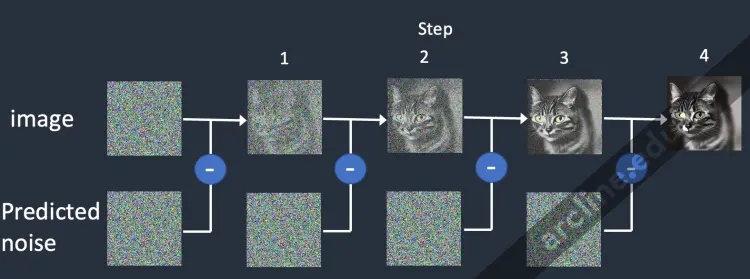
Dưới đây là cách hình ảnh tiến triển trong mỗi bước lấy mẫu.
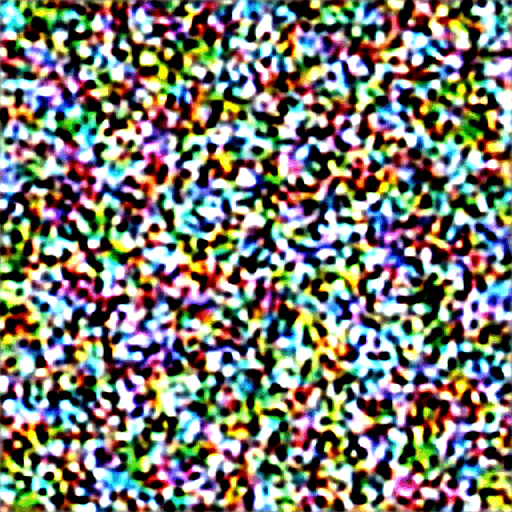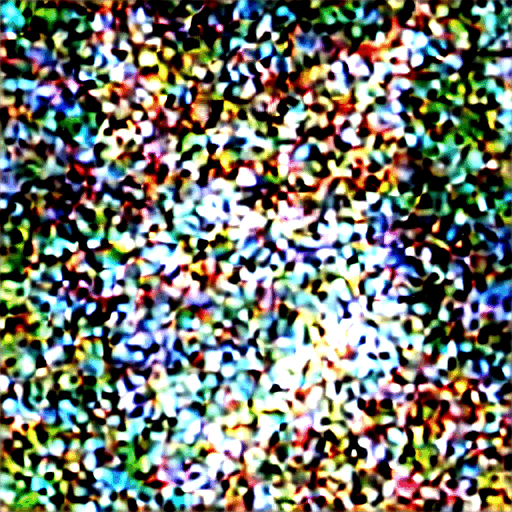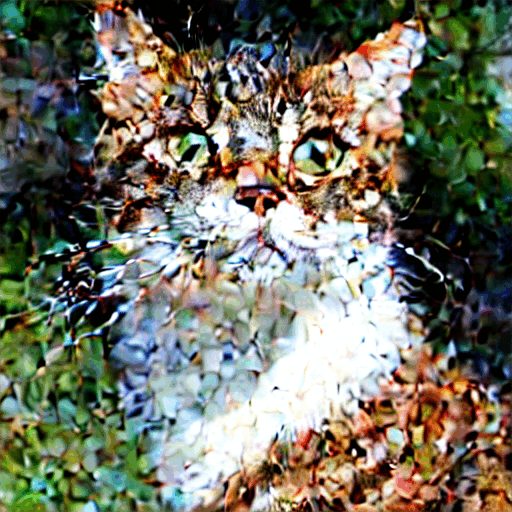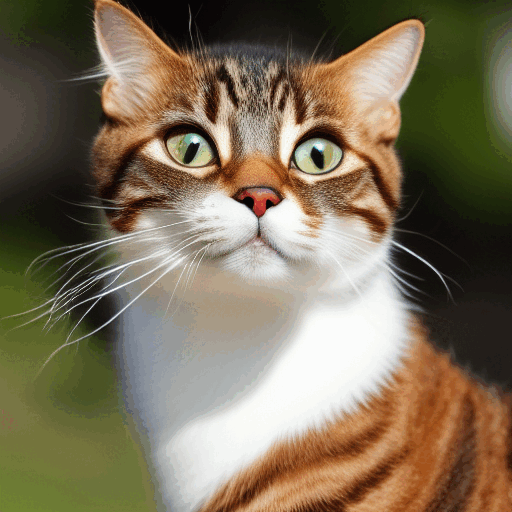
Ảnh ở mỗi bước lấy mẫu.
Lịch trình nhiễu (Noise schedule)
Hình ảnh thay đổi từ nhiễu đến sạch. Bạn có tự hỏi liệu bộ dự đoán nhiễu không hoạt động tốt trong các bước ban đầu không? Thực tế, điều này chỉ đúng một phần. Nguyên nhân thực sự là chúng ta cố gắng đạt được nhiễu mong đợi ở mỗi bước lấy mẫu. Điều này được gọi là lịch trình nhiễu. Dưới đây là một ví dụ.
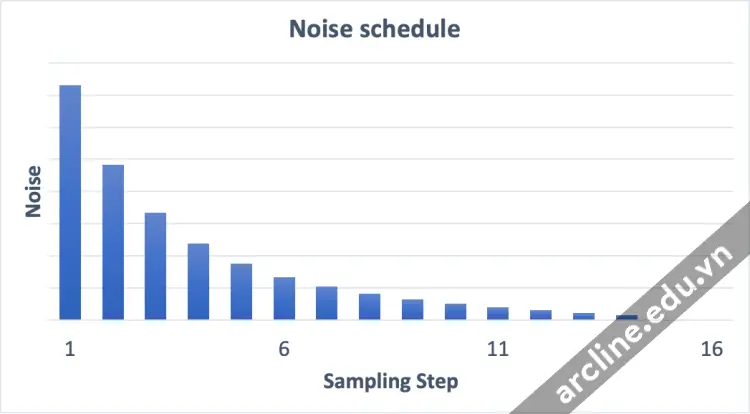
Một lịch trình nhiễu cho 15 bước lấy mẫu.
Lịch trình nhiễu là một điều chúng ta định nghĩa. Chúng ta có thể chọn trừ đi cùng một lượng nhiễu ở mỗi bước. Hoặc chúng ta có thể trừ nhiễu nhiều hơn ở đầu, như ở trên. Trình lấy mẫu trừ đi đúng đủ nhiễu ở mỗi bước để đạt được nhiễu mong đợi ở bước tiếp theo. Đó là những gì bạn thấy trong hình ảnh từng bước.
Image-to-image
Image-to-image là một phương pháp được đề xuất lần đầu trong phương pháp SDEdit. SDEdit có thể được áp dụng cho bất kỳ mô hình lan truyền nào. Do đó, chúng ta có hình ảnh đến hình ảnh cho mô hình Stable Diffusion (một mô hình lan truyền tiềm ẩn).
Một hình ảnh đầu vào và một đoạn văn ghi nhập văn bản được cung cấp như đầu vào trong hình ảnh đến hình ảnh. Hình ảnh được tạo ra sẽ được điều kiện bởi cả hình ảnh đầu vào và đoạn văn ghi nhập văn bản. Ví dụ, sử dụng hình vẽ tay người không chuyên và đoạn văn ghi nhập “ảnh táo xanh hoàn hảo với thân, giọt nước, ánh sáng dramatique” như đầu vào, hình ảnh đến hình ảnh có thể biến nó thành một bức vẽ chuyên nghiệp:

Image-to-image
Dưới đây là quy trình từng bước.
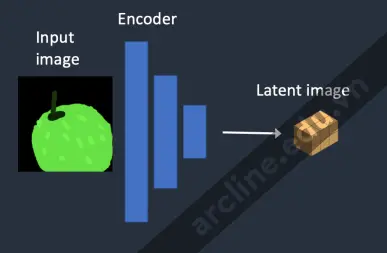
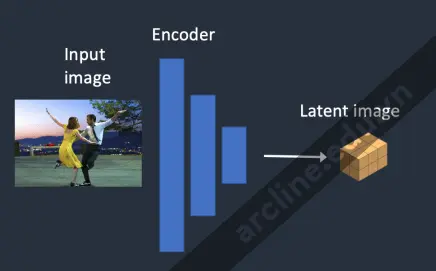
Bước 1. Hình ảnh đầu vào được mã hóa thành không gian tiềm ẩn.
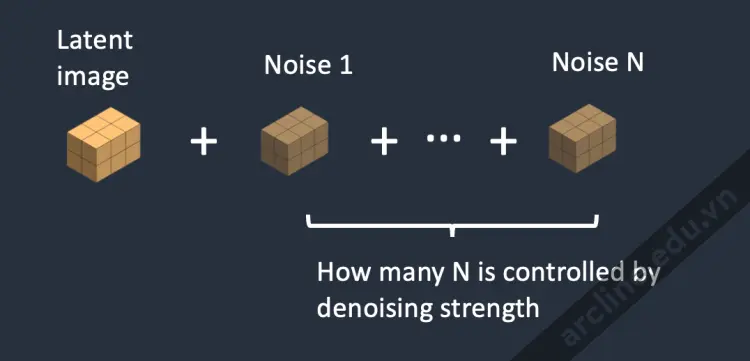
Bước 2. Nhiễu được thêm vào hình ảnh tiềm ẩn. Sức mạnh làm sạch kiểm soát mức độ nhiễu được thêm vào. Nếu là 0, không thêm nhiễu. Nếu là 1, thêm lượng nhiễu tối đa để hình ảnh tiềm ẩn trở thành một ma trận ngẫu nhiên hoàn toàn.
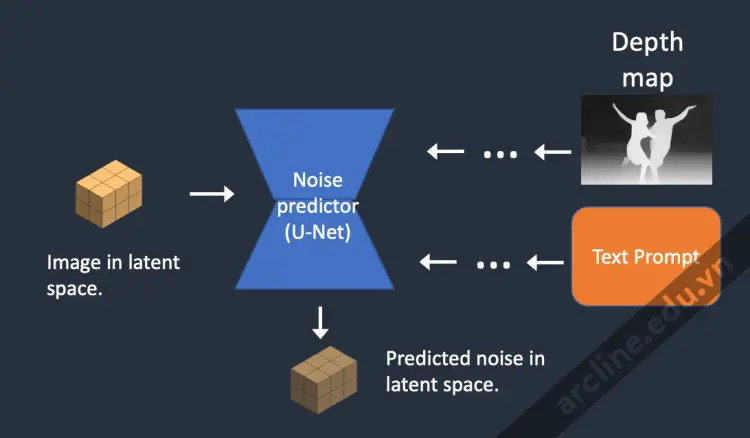
Bước 3. Bộ dự đoán nhiễu U-Net lấy hình ảnh ẩn nhiễu tiềm ẩn và đoạn văn ghi nhập văn bản như đầu vào và dự đoán nhiễu trong không gian tiềm ẩn (một ma trận 4x64x64).
Bước 4. Trừ đi nhiễu tiềm ẩn khỏi hình ảnh tiềm ẩn. Điều này trở thành hình ảnh tiềm ẩn mới của bạn.
Các bước 3 và 4 được lặp lại trong một số bước lấy mẫu nhất định, ví dụ: 20 lần.
Bước 5. Cuối cùng, bộ giải mã VAE chuyển đổi hình ảnh tiềm ẩn trở lại không gian pixel. Đây là hình ảnh bạn nhận được sau khi chạy hình ảnh đến hình ảnh.
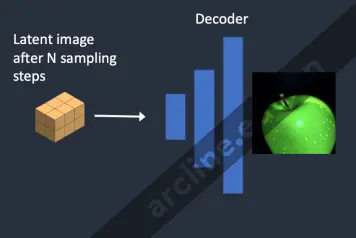
Vì vậy, bây giờ bạn đã biết hình ảnh đến hình ảnh là gì: Tất cả những gì nó làm chỉ là đặt hình ảnh tiềm ẩn ban đầu với một chút nhiễu và một chút hình ảnh đầu vào. Đặt sức mạnh làm sạch là 1 tương đương với từ văn bản đến hình ảnh vì hình ảnh tiềm ẩn ban đầu hoàn toàn là nhiễu ngẫu nhiên.
Inpainting
Inpainting thực sự chỉ là một trường hợp cụ thể của hình ảnh đến hình ảnh. Nhiễu được thêm vào các phần của hình ảnh bạn muốn điền vào. Lượng nhiễu cũng được điều khiển tương tự bởi sức mạnh làm sạch.
Độ sâu đến hình ảnh (Depth-to-image)
Depth-to-image là một cải tiến cho hình ảnh đến hình ảnh; nó tạo ra các hình ảnh mới với điều kiện bổ sung bằng cách sử dụng bản đồ độ sâu.
Bước 1. Hình ảnh đầu vào được mã hóa thành trạng thái tiềm ẩn
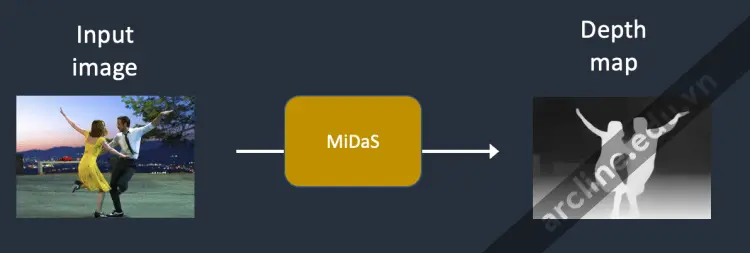
Bước 2. MiDaS (một mô hình độ sâu AI) ước tính bản đồ độ sâu từ hình ảnh đầu vào.
Bước 3. Nhiễu được thêm vào hình ảnh tiềm ẩn. Sức mạnh làm sạch kiểm soát mức độ nhiễu được thêm vào. Nếu sức mạnh làm sạch là 0, không thêm nhiễu. Nếu sức mạnh làm sạch là 1, thêm nhiễu tối đa để hình ảnh tiềm ẩn trở thành một ma trận ngẫu nhiên.
Bước 4. Bộ dự đoán nhiễu ước tính nhiễu của không gian tiềm ẩn, được điều kiện bởi đoạn văn ghi nhập văn bản và bản đồ độ sâu.
Bước 5. Trừ đi nhiễu tiềm ẩn khỏi hình ảnh tiềm ẩn. Điều này trở thành hình ảnh tiềm ẩn mới của bạn.
Các bước 4 và 5 được lặp lại trong số lần lấy mẫu.
Bước 6. Bộ giải mã VAE giải mã hình ảnh tiềm ẩn. Bây giờ bạn có được hình ảnh cuối cùng từ độ sâu đến hình ảnh.
Chúng ta có một giá trị CFG là gì?
Bài viết này sẽ không hoàn chỉnh nếu không giải thích về Classifier-Free Guidance (CFG), một giá trị mà các nghệ sĩ AI tinh chỉnh hàng ngày. Để hiểu điều đó, chúng ta cần phải đề cập đến phiên bản tiền nhiệm của nó, hướng dẫn của bộ phân loại…
Hướng dẫn bằng bộ phân loại
Hướng dẫn bằng bộ phân loại là một cách để tích hợp các nhãn hình ảnh trong các mô hình lan truyền. Bạn có thể sử dụng một nhãn để hướng dẫn quá trình lan truyền. Ví dụ, nhãn “mèo” điều hướng quá trình lan truyền đảo ngược để tạo ra ảnh của mèo.
Thang điểm hướng dẫn bằng bộ phân loại là một tham số để kiểm soát mức độ quá trình lan truyền làm theo nhãn.
Dưới đây là một ví dụ mà tôi đã đánh cắp từ bài báo này. Giả sử có 3 nhóm hình ảnh với các nhãn “mèo”, “chó” và “người”. Nếu quá trình lan truyền không được hướng dẫn, mô hình sẽ lấy mẫu từ tổng dân số của mỗi nhóm, nhưng đôi khi nó có thể lấy mẫu ảnh có thể phù hợp với hai nhãn, ví dụ, một cậu bé vuốt ve một con chó.
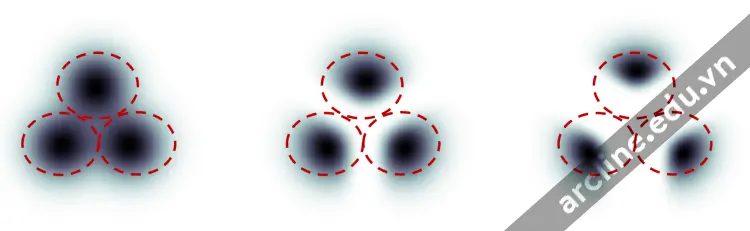
Hướng dẫn bộ phân loại. Bên trái: không hướng dẫn. Ở giữa: hướng dẫn quy mô nhỏ. Bên phải: hướng dẫn quy mô lớn.
Với sự hướng dẫn bằng bộ phân loại cao, các hình ảnh được tạo ra bởi mô hình lan truyền sẽ thiên về các ví dụ cực đoan hoặc rõ ràng. Nếu bạn yêu cầu mô hình cho một con mèo, nó sẽ trả về một hình ảnh rõ ràng là một con mèo và không có gì khác.
Thang điểm hướng dẫn bằng bộ phân loại kiểm soát mức độ mà hướng dẫn được tuân theo. Trong hình trên, quá trình lấy mẫu ở bên phải có thang điểm hướng dẫn bằng bộ phân loại cao hơn so với quá trình ở giữa. Trong thực tế, giá trị thang này đơn giản là bội số cho thuật ngữ đẩy hướng về dữ liệu có nhãn đó.
Hướng dẫn không cần bộ phân loại
Mặc dù hướng dẫn bằng bộ phân loại đã đạt được hiệu suất phá vỡ kỷ lục, nhưng nó cần một mô hình bổ sung để cung cấp hướng dẫn đó. Điều này đã đặt ra một số khó khăn trong quá trình đào tạo.
Hướng dẫn không cần bộ phân loại, theo cách gọi của tác giả, là một cách để đạt được “hướng dẫn bộ phân loại mà không cần bộ phân loại”. Thay vì sử dụng các nhãn lớp và một mô hình riêng biệt để hướng dẫn, họ đề xuất sử dụng chú thích hình ảnh và đào tạo một mô hình lan truyền có điều kiện, chính xác như mô hình chúng ta đã thảo luận trong từ văn bản đến hình ảnh.
Họ đặt phần phân loại làm điều kiện của bộ dự đoán nhiễu U-Net, đạt được sự hướng dẫn “không cần bộ phân loại” (tức là không cần một bộ phân loại hình ảnh riêng biệt) trong việc tạo ra hình ảnh.
Giá trị CFG
Bây giờ chúng ta có một quá trình lan truyền không cần bộ phân loại thông qua điều kiện, làm thế nào chúng ta kiểm soát mức độ hướng dẫn nên được tuân theo?
Thang điểm hướng dẫn không cần bộ phân loại (CFG) là một giá trị kiểm soát mức độ mà câu hỏi văn bản định hình quá trình lan truyền. Việc tạo ra hình ảnh không có điều kiện (tức là văn bản định hình bị bỏ qua) khi nó được đặt thành 0. Một giá trị cao hơn hướng dẫn quá trình lan truyền đến văn bản định hình.
Stable Diffusion v1 so với v2
Đây đã là một bài viết dài, nhưng nó sẽ không hoàn chỉnh nếu không so sánh sự khác biệt giữa các mô hình v1 và v2.
Sự khác biệt trong mô hình
Stable Diffusion v2 sử dụng OpenClip cho việc nhúng văn bản. Stable Diffusion v1 sử dụng Open AI’s CLIP ViT-L/14 cho việc nhúng văn bản. Những lý do cho sự thay đổi này là
- OpenClip lớn gấp năm lần. Một mô hình mã hóa văn bản lớn hơn cải thiện chất lượng hình ảnh.
- Mặc dù các mô hình CLIP của Open AI là mã nguồn mở, nhưng các mô hình đã được đào tạo với dữ liệu độc quyền. Chuyển sang mô hình OpenClip mang lại sự minh bạch hơn cho nhà nghiên cứu trong việc nghiên cứu và tối ưu hóa mô hình. Điều này tốt hơn cho phát triển dài hạn.
Sự khác biệt trong dữ liệu đào tạo
Stable Diffusion v1.4 được đào tạo với
- 237k bước ở độ phân giải 256×256 trên tập dữ liệu laion2B-en.
- 194k bước ở độ phân giải 512×512 trên tập dữ liệu laion-high-resolution.
- 225k bước ở độ phân giải 512×512 trên “laion-aesthetics v2 5+“, với 10% bỏ qua việc điều kiện văn bản.
Stable Diffusion v2 được đào tạo với
- 550k bước ở độ phân giải 256×256 trên một phần của tập dữ liệu LAION-5B đã lọc loại bỏ nội dung khiêu dâm rõ ràng, sử dụng bộ phân loại LAION-NSFW với punsafe=0.1 và điểm thẩm định >= 4.5.
- 850k bước ở độ phân giải 512×512 trên cùng tập dữ liệu trên các hình ảnh với độ phân giải >= 512×512.
- 150k bước sử dụng v-objective trên cùng tập dữ liệu.
- Tiếp tục thêm 140k bước trên hình ảnh 768×768.
Stable Diffusion v2.1 được tinh chỉnh thêm trên v2.0
- Thêm 55k bước trên cùng tập dữ liệu (với punsafe=0.1)
- Thêm 155k bước bổ sung với punsafe=0.98
Vì vậy, cơ bản là họ đã tắt bộ lọc NSFW trong các bước đào tạo cuối cùng.
Sự khác biệt trong kết quả
Người dùng thông thường thấy khó khăn hơn khi sử dụng Stable Diffusion v2 để kiểm soát phong cách và tạo ra các người nổi tiếng. Mặc dù Stability AI không rõ ràng loại bỏ tên của nghệ sĩ và người nổi tiếng, hiệu ứng của họ yếu hơn nhiều trong v2. Điều này có thể do sự khác biệt trong dữ liệu đào tạo. Dữ liệu độc quyền của Open AI có thể chứa nhiều tác phẩm nghệ thuật và ảnh người nổi tiếng hơn. Dữ liệu của họ có thể đã được lọc kỹ lưỡng để mọi thứ và mọi người trông tốt và đẹp hơn.
Để biết thêm thông tin chi tiết về Stable Diffusion có thể tìm hiểu thêm tại khóa học Stable Diffusion – Midjourney tại Arcline Academy hoặc có thể tham khảo thêm thông tin các khóa học khác tại đây
Trụ sở chính: 32/19 Nghĩa Hòa, Phường 06, Q. Tân Bình, TPHCM (Nhà Thờ Nghĩa Hòa – Khu Bắc Hải)
Trụ sở miền Tây: L30-09, Đường số 43, Khu Dân cư Stella Megacity, P. Bình Thủy, Q. Bình Thủy, Tp. Cần Thơ
Hotline: 0988 363 967
