LoRA models là những Stable Diffusion models nhỏ gọn áp dụng những thay đổi nhỏ lên các checkpoint models chuẩn. Chúng thường nhỏ gọn hơn từ 10 đến 100 lần so với checkpoint models. Điều này khiến chúng rất hấp dẫn đối với những người sở hữu một bộ sưu tập lớn các models.
Đây là hướng dẫn cho người mới bắt đầu, những ai chưa từng sử dụng models LoRA trước đây. Bạn sẽ tìm hiểu về models LoRA, nơi tìm kiếm chúng và cách sử dụng chúng trong giao diện người dùng (GUI) của AUTOMATIC1111. Sau đó, bạn sẽ tìm thấy một số demo về models LoRA ở phần cuối.
LoRA Models là gì?
LoRA (Low-Rank Adaptation) là một kỹ thuật đào tạo dùng để tinh chỉnh các Stable Diffusion models.
Nhưng chúng ta đã có các kỹ thuật đào tạo khác như Dreambooth và textual inversion. Vậy điều đặc biệt của LoRA là gì? LoRA mang lại sự cân đối tốt giữa kích thước file và khả năng đào tạo. Dreambooth mạnh mẽ nhưng tạo ra các file model lớn (2-7 GBs). Textual inversions nhỏ gọn (khoảng 100 KBs), nhưng khả năng của bạn bị hạn chế.
LoRA nằm giữa hai kỹ thuật trên. Kích thước file của nó thể quản lý dễ dàng hơn (2 – 200 MBs), và khả năng đào tạo tương đối ổn.
Những người sử dụng Stable Diffusion thích thử nghiệm với các models có thể nói cho bạn biết ổ lưu trữ của họ nhanh chóng đầy lên. Bởi vì kích thước lớn, việc duy trì một bộ sưu tập trên máy tính cá nhân là khó khăn. LoRA là một giải pháp tuyệt vời cho vấn đề lưu trữ này.
Giống như textual inversion, bạn không thể sử dụng models LoRA một mình. Chúng phải được sử dụng cùng với một file checkpoint model. LoRA chỉnh sửa styles bằng cách áp dụng những thay đổi nhỏ lên file model đi kèm.
LoRA hoạt động như thế nào?
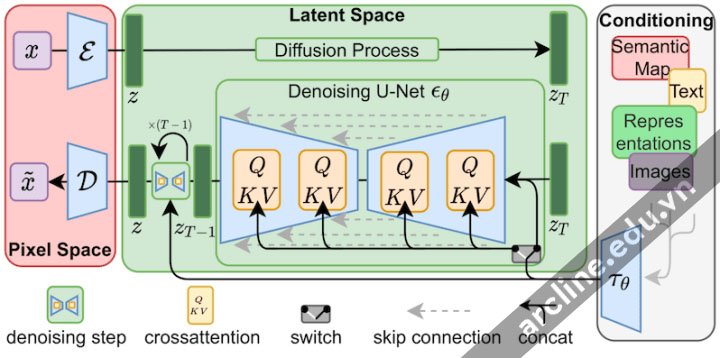
LoRA áp dụng những thay đổi nhỏ vào phần quan trọng nhất của Stable Diffusion models: Các lớp cross-attention. Đó là phần của model nơi hình ảnh và dấu nhắc gặp nhau. Các nhà nghiên cứu đã tìm ra rằng chỉ cần tinh chỉnh phần này của model để đạt được kết quả đào tạo tốt. Các lớp cross-attention là những phần màu vàng trong kiến trúc Stable Diffusion model dưới đây.
LoRA tinh chỉnh các lớp cross-attention (các phần QKV của U-Net noise predictor). (Hình vẽ từ bài báo Stable Diffusion.)
Trọng số của một lớp cross-attention được sắp xếp trong các ma trận. Các ma trận chỉ là một số lượng lớn số liệu được sắp xếp theo cột và hàng, giống như trên một bảng tính Excel. LoRA model tinh chỉnh một model bằng cách thêm trọng số của nó vào các ma trận này.
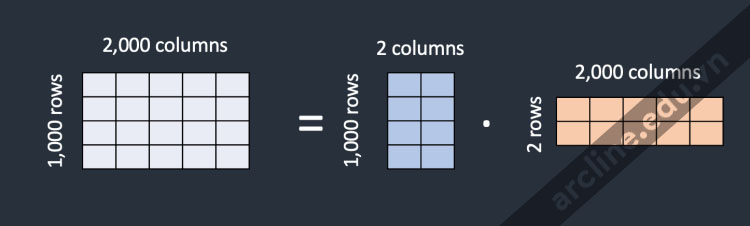
Làm thế nào mà file model LoRA có thể nhỏ hơn nếu chúng cần lưu trữ cùng số lượng trọng số? Mẹo của LoRA là phân rã một ma trận thành hai ma trận nhỏ hơn (low-rank). Nó có thể lưu trữ ít số liệu hơn rất nhiều bằng cách này. Hãy minh họa điều này với ví dụ sau.
Giả sử model có một ma trận với 1,000 hàng và 2,000 cột. Đó là 2,000,000 số (1,000 x 2,000) cần lưu trữ trong file model. LoRA phân rã ma trận thành một ma trận 1,000-by-2 và một ma trận 2-by-2,000. Đó chỉ là 6,000 số (1,000 x 2 + 2 x 2,000), ít hơn 333 lần. Đó là lý do tại sao file LoRA nhỏ hơn rất nhiều.
LoRA phân rã một ma trận lớn thành hai ma trận nhỏ, low-rank
Trong ví dụ này, hạng của các ma trận là 2. Nó thấp hơn rất nhiều so với kích thước gốc, vì vậy chúng được gọi là ma trận low-rank. Hạng có thể thấp đến mức 1.
Nhưng có hại gì khi sử dụng một mẹo như vậy không? Các nhà nghiên cứu đã tìm thấy việc làm như vậy trong các lớp cross-attention không ảnh hưởng nhiều đến khả năng tinh chỉnh. Vì vậy, chúng ta ổn.
Nơi tìm kiếm LoRA models?
Civtai
LoRA models trên Civitai.
Nơi đầu tiên để tìm kiếm LoRA là Civitai. Trang web này lưu trữ một bộ sưu tập lớn của LoRA models. Áp dụng bộ lọc LORA để chỉ xem LoRA models. Bạn có thể thấy rằng chúng có xu hướng tương tự: chân dung nữ, anime, phong cách minh họa thực tế, v.v.
(Hãy cảnh giác rằng có rất nhiều nội dung NSFW trên Civitai. Hãy chắc chắn bật bộ lọc NSFW nếu bạn không muốn nhìn thấy điều gì đó bạn không thể bỏ qua…)
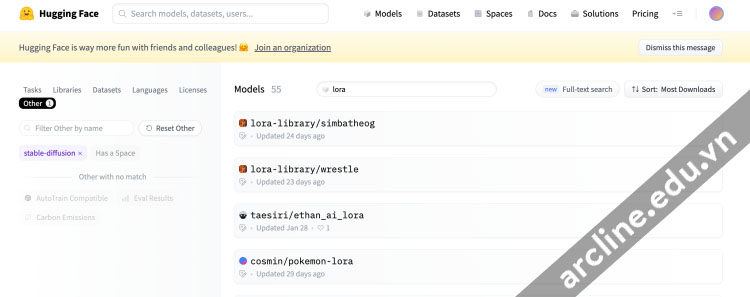
LoRA models trên Hugging Face
Hugging Face
Hugging Face là một nguồn tốt khác của thư viện LoRA. Bạn sẽ tìm thấy nhiều loại LoRA models hơn. Nhưng không có nhiều LoRA models ở đó. Bộ sưu tập của họ nhỏ hơn rất nhiều.
Trong phần này, bạn sẽ tìm thấy hướng dẫn để sử dụng LoRA model trong AUTOMATIC1111 Stable Diffusion GUI. Bạn có thể sử dụng GUI này trên Windows, Mac, hoặc Google Colab.
AUTOMATIC1111 hỗ trợ LoRA một cách tự nhiên. Bạn không cần cài đặt bất kỳ tiện ích mở rộng nào.
Bước 1: Cài đặt LoRA model
Để cài đặt LoRA models trong webui của AUTOMATIC1111, đặt các file model vào thư mục sau.
stable-diffusion-webui/models/Lora
Bước 2: Sử dụng LoRA model
Để sử dụng một LoRA model, đặt cụm từ sau vào dấu nhắc.
lora:filename:multiplier
“filename” là tên file của LoRA model, không kể phần mở rộng (.pt, .bin, v.v).
“multiplier” là trọng số được áp dụng cho LoRA model. Mặc định là 1. Đặt nó thành 0 sẽ vô hiệu hóa model.
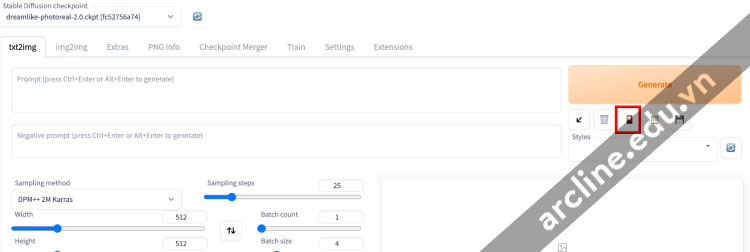
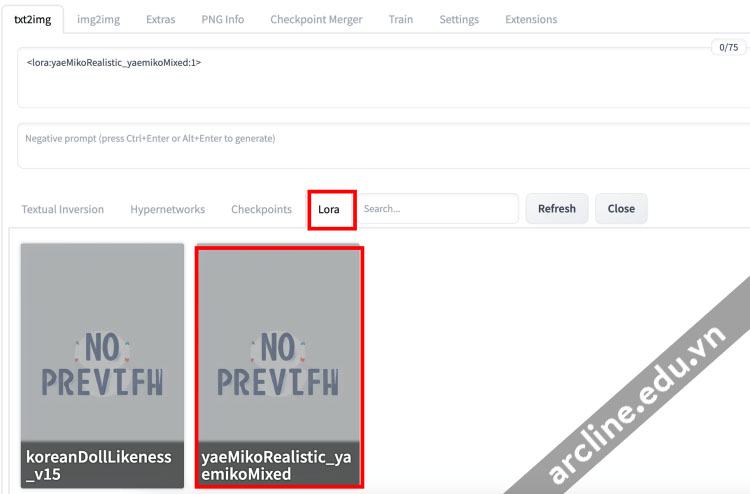
Làm thế nào bạn có thể chắc chắn rằng tên file đúng? Thay vì viết cụm từ này, bạn nên nhấp vào nút model.
Nhấp vào tab Lora. Bạn sẽ thấy danh sách các LoRA models đã cài đặt. Nhấp vào model bạn muốn sử dụng.
Cụm từ LoRA sẽ được chèn vào dấu nhắc.
Ghi chú về việc sử dụng LoRA
Bạn có thể điều chỉnh multiplier để tăng lên hoặc giảm xuống hiệu ứng. Đặt multiplier là 0 sẽ vô hiệu hóa LoRA model. Bạn có thể điều chỉnh hiệu ứng phong cách từ 0 đến 1.
Một số LoRA models được đào tạo với Dreambooth. Bạn sẽ cần bao gồm một từ khóa kích hoạt để sử dụng LoRA model. Bạn có thể tìm thấy từ khóa kích hoạt trên trang của model.
Tương tự như embeddings, bạn có thể sử dụng nhiều LoRA models cùng một lúc. Bạn cũng có thể sử dụng chúng với embeddings.
Trong AUTOMATIC1111, cụm từ LoRA không phải là một phần của dấu nhắc. Nó sẽ bị xóa sau khi LoRA model được áp dụng. Điều đó có nghĩa là bạn không thể sử dụng cú pháp dấu nhắc như [keyword1:keyword2: 0.8] với chúng.
Một số LoRA models
Dưới đây là lựa chọn thiên vị của tôi về các LoRA models.
Shukezouma
LoRA model Shukezouma mang lại một chủ đề về họa tiết mực Trung Quốc phong cách. Shukezouma có nghĩa là không gian trống (thường thấy trong tranh Trung Quốc) của bức tranh rộng đến mức một con ngựa có thể đi qua được.
Trang LoRA Model Shukezouma
Sử dụng LoRA này với model theo phong cách Trung Quốc là Guo Feng.
Từ khóa kích hoạt: shukezouma
Gợi ý:
(shukezouma:0.5) ,lora:Moxin_Shukezouma:1 , tranh Trung Quốc, nửa thân, nữ, khuôn mặt hoàn hảo đối xứng, trang phục Trung Quốc chi tiết, núi, hoa, 1girl, hổ
Gợi ý phủ định:
biến dạng, xấu, tồi, non trẻ
LoRA model Shukezouma
Phong cách Akemi Takada (thập kỷ 1980)
Akemi Takada là một họa sĩ manga Nhật Bản. Đây dành cho bạn nếu bạn thích anime Nhật Bản trong thập kỷ 1980 và 1990.
Sử dụng với model AbyssOrangeMix2.
Gợi ý:
takada akemi, Tifa lockhart như một phù thủy, Final Fantasy VII, 1girl, vòng một nhỏ, đôi mắt đẹp, tóc nâu, mỉm cười, mắt đỏ, highres, bông tai kim cương, tóc dài, tóc phân chia bên, tóc sau tai, nửa thân trên, váy thời trang, trong nhà, bar 1980s (phong cách), tranh (phương tiện), nghệ thuật retro, màu nước (phương tiện) lora:akemiTakada1980sStyle_1:0.6
Gợi ý phủ định:
(chất lượng tồi, chất lượng thấp:1.4), (tranh của bad-artist-anime:0.9), (tranh của bad-artist:0.9), watermark, văn bản, lỗi, mờ, nghệ thuật jpeg, cắt, chất lượng tồi, chất lượng thấp, chất lượng bình thường, nghệ thuật jpeg, chữ ký, watermark, tên người dùng, tên họa sĩ, giải phẫu xấu
Cyberpunk 2077 Tarot card
LoRA model này tạo ra cyborg và các thành phố với phong cách cyberpunk tương lai.
Được sử dụng với model Anything v4.5.
Gợi ý:
cyberpunk, tarot card, chụp close up, chân dung, cơ thể bionic, mèo, thanh niên, khuôn mặt đối xứng hoàn hảo của con người, áo khoác da kim loại, mạch điện, phố thành phố ở nền sau, ánh sáng tự nhiên, kiệt tác lora:cyberpunk2077Tarot_tarotCard512x1024:0.6
Gợi ý phủ định:
(chất lượng tồi, chất lượng thấp:1.4), (tranh của bad-artist-anime:0.9), (tranh của bad-artist:0.9), watermark, văn bản, lỗi, mờ, nghệ thuật jpeg, cắt, chất lượng tồi, chất lượng thấp, chất lượng bình thường, nghệ thuật jpeg, chữ ký, watermark, tên người dùng, tên họa sĩ, giải phẫu xấu, vòng một to