Text2video là một nhiệm vụ khó khăn khi biến mô tả văn bản thành video. Mô hình text-to-video dựa trên Diffusion đang cải thiện với tốc độ nhanh chóng. Bây giờ, những mô hình này trở nên hữu ích và có thể chạy cục bộ trên máy của bạn. Trong bài viết này, bạn sẽ tìm hiểu một số cách để chuyển đổi một đề xuất văn bản thành video.
1. AnimateDiff
2. ModelScope
3. Deforum
Phần mềm
Chúng ta sẽ sử dụng giao diện AUTOMATIC1111 Stable Diffusion. Bạn có thể sử dụng giao diện này trên Windows, Mac hoặc Google Colab.
1. AnimateDiff
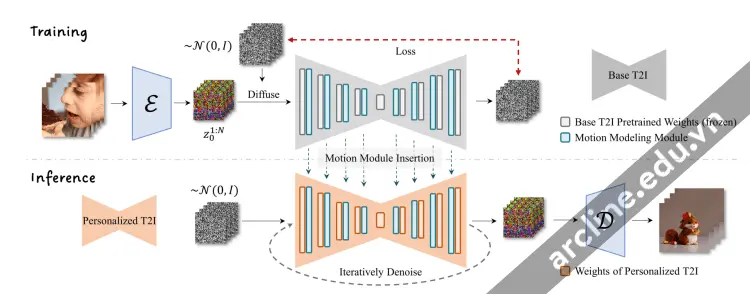
AnimateDiff là một mô-đun text-to-video cho Stable Diffusion. Nó đã được huấn luyện bằng cách cung cấp các đoạn video ngắn cho một mô hình chuyển động để học cách khung video tiếp theo nên trông như thế nào. Sau khi prior này được học, animateDiff tiêm vào mô-đun chuyển động vào bộ dự đoán tiếng ồn U-Net của mô hình Stable Diffusion để tạo ra một video dựa trên mô tả văn bản.
AnimateDiff pipeline (Image from the AnimateDiff paper)
Vì vậy, bạn thực sự không thể kiểm soát điều gì xảy ra trong video. Chúng xuất phát từ những gì mô hình đã học từ dữ liệu huấn luyện.
Bạn có thể sử dụng AnimateDiff với bất kỳ mô hình kiểm tra Stable Diffusion nào và LoRA.
Cài đặt tiện ích AnimateDiff
Google Colab Notebook
Việc cài đặt tiện ích AnimateDiff trên sổ ghi chú Stable Diffusion của chúng ta rất dễ dàng. Bạn chỉ cần chọn tiện ích AnimateDiff,
Windows hoặc Mac
Làm theo các bước sau để cài đặt tiện ích AnimateDiff trong AUTOMATIC1111.
1. Bắt đầu AUTOMATIC1111 Web-UI bình thường.
2. Điều hướng đến Trang mở rộng.
3. Nhấp vào tab Cài đặt từ URL.
4. Nhập URL sau vào trường lưu trữ git của tiện ích.
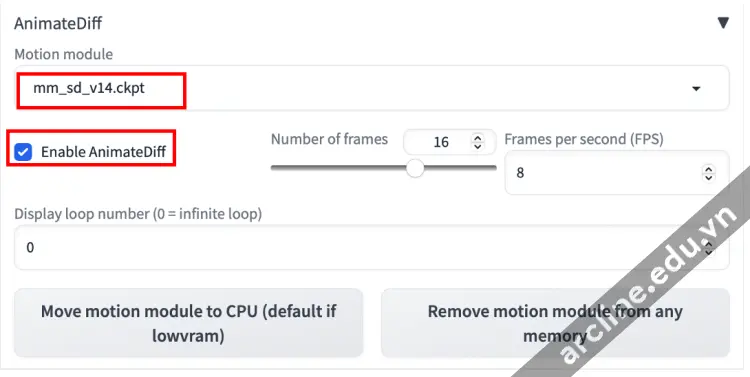
Để sử dụng AnimateDiff trong AUTOMATIC1111, điều hướng đến trang txt2img. Trong phần AnimateDiff,
Bật AnimateDiff: Có Mô-đun
Chuyển động: Có hai mô-đun chuyển động bạn có thể lựa chọn. Mô hình v1.4 tạo ra nhiều chuyển động hơn, nhưng mô hình v1.5 tạo ra những hình ảnh rõ ràng hơn.
Sau đó, viết một gợi ý và một gợi ý phủ định như thông thường. Ví dụ
1girl, looking at viewer, anime, cherry blossoms
disfigured, deformed, ugly
Bạn có thể chọn bất kỳ mô hình v1 nào. Hãy sử dụng mô hình Anything v3 cho ví dụ này.
CFG: 15 (Điều này RẤT QUAN TRỌNG để đặt nó ở một giá trị cao từ 10 – 25)
Sampler: DPM++2M Karass
Dưới đây là những đoạn video từ các mô hình chuyển động v1.4 và v1.5.
AnimateDiff v1.4 motion model (CFG 15)
AnimateDiff v1.5 model (CFG 20)
Nhìn chung, bạn sẽ thấy mô hình chuyển động v1.4 tạo ra nhiều chuyển động hơn và mô hình v1.5 tạo ra những hình ảnh rõ ràng hơn.
Mẹo
Dưới đây là một số mẹo để bạn tăng cơ hội thành công của mình.
Tăng tỷ lệ CFG nếu bạn thấy ảnh trông nhạt màu. Thông thường, bạn cần đặt nó ở giữa 10 và 25.
Thử chuyển đổi mô-đun chuyển động (v1.4 và v1.5) nếu bạn thấy dấu watermark trên hình ảnh.
Bạn có thể sử dụng LoRA với AnimateDiff.
Giữ số khung ảnh ở mức 16 để có hiệu suất tối ưu vì đây là số khung ảnh mà nó được huấn luyện.
Bạn SẼ cần phải chọn lựa cẩn thận để có những video tốt. Tạo thêm nhiều video!
Thay đổi gợi ý nếu bạn nhận được hai video ngắn trong một video.
Ví dụ gợi ý và cài đặt
Sóng biển
Gợi ý:
A beautiful beach, waves
Gợi ý phủ định:
watermark, letters
Tỷ lệ CFG: 20
Mô hình: Dreamshaper 5
Mô-đun chuyển động: v1.4
Cô gái mặc áo len đỏ
Gợi ý:
1girl, tohsaka rin, solo, long hair, sweater, red sweater, looking at viewer, walking <lora:3DMM_V12:1>
Gợi ý phủ định:
disfigured, deformed, ugly
Tỷ lệ CFG: 16
Mô hình: Rev Animated
LoRA: Phong cách dựng hình 3D
Mô-đun chuyển động: v1.4
Người phụ nữ chân thực
Gợi ý:
close up photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores
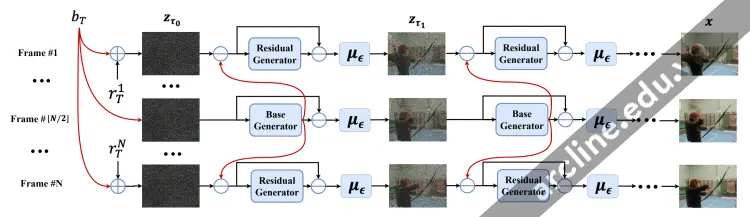
Video generation pipeline of Modelscope (from Modelscope paper)
ModelScope là một mô hình dựa trên Diffusion để tạo video từ văn bản. Ý tưởng đằng sau mô hình là quan sát rằng các khung ảnh của video chủ yếu giống nhau. ModeScope là một mô hình diffusion ẩn. Vì vậy, khung đầu tiên bắt đầu như một tensor nhiễu ẩn, giống như việc chuyển đổi văn bản thành hình ảnh của Stable Diffusion. Điều đột phá ở đây là mô hình phân rã nhiễu thành hai phần: (1) nhiễu cơ bản và (2) nhiễu dư. Nhiễu cơ bản được chia sẻ trên TẤT CẢ các khung ảnh. Nhiễu dư thay đổi trong mỗi khung ảnh.
Sử dụng bản demo ModelScope nếu bạn không muốn cài đặt tiện ích trong AUTOMATIC1111.
Cài đặt ModelScope trong AUTOMATIC1111
Bạn sẽ cần cài đặt tiện ích text2video. Làm theo các bước sau để cài đặt tiện ích trong AUTOMATIC1111.
Google Colab
Cài đặt tiện ích text2video trong sổ ghi chú Google Colab của Stable Diffusion của chúng tôi rất dễ dàng. Bạn chỉ cần chọn tiện ích text2video.
Windows và Mac
1. Bắt đầu AUTOMATIC1111 Web-UI bình thường.
2. Điều hướng đến Trang mở rộng.
3. Nhấp vào tab Cài đặt từ URL.
4. Nhập URL sau vào trường lưu trữ git của tiện ích.
5. Đợi thông báo xác nhận rằng việc cài đặt đã hoàn tất.
6. Khởi động lại webUI hoàn toàn. (Bằng cách khởi động lại terminal.)
LƯU Ý: Nếu bạn gặp lỗi liên quan đến việc nhập khẩu tqdm, bạn sẽ cần cài đặt lại phiên bản cụ thể của tqdm. Chạy lệnh sau trong Ứng dụng Terminal trong stable-diffusion-webui
Windows:
.\venv\Scripts\pip.exe install tqdm==4.65.0
Mac:
./venv/bin/pip install tqdm==4.65.0
7. Tạo các thư mục mô hình. Bạn cần tạo cấu trúc thư mục.
stable-diffusion-webui\models\text2video\t2v
Nói cách khác, tạo thư mục mô hình text2video bên trong thư mục models. Sau đó tạo thư mục t2v bên trong thư mục text2video.
Tải xuống các tệp mô hình text2video tại đây và đặt chúng trong thư mục t2v. Bạn cần 4 tệp sau
VQGAN_autoencoder.pth
configuration.json
open_clip_pytorch_model.bin
text2video_pytorch_model.pth
Đó là nhiều công việc! Nhưng đó là tất cả… cho đến nay.
Fine-tuned models
Tương tự như Stable Diffusion, Modelscope cũng có các mô hình được điều chỉnh tinh chỉnh. Chúng được tạo ra thông qua việc huấn luyện bổ sung. Bạn có thể tìm danh sách các mô hình được điều chỉnh tinh chỉnh ở đây.
Zeroscope: Watermark-free text-to-video
Bạn có thể đã nhận thấy dấu watermark trên một số video được tạo ra bằng mô hình cơ bản của Modelscope. Có một mô hình được điều chỉnh tinh chỉnh để giải quyết vấn đề này: Zeroscope v2.
2. Bạn cần 4 tệp trong thư mục này. Hai tệp đầu tiên có thể được tìm thấy ở đây. Hai tệp còn lại có thể được tải xuống từ kho mô hình cơ bản của Modelscope. (Hoặc sao chép từ thư mục mô hình cơ bản)
open_clip_pytorch_model.bin
text2video_pytorch_model.pth
VQGAN_autoencoder.pth
configuration.json
Bây giờ hãy tạo video bằng mô hình mới. Mô hình này tạo ra các video với kích thước 576 x 320 pixel.
Chiều rộng: 576 (Bạn phải sử dụng chiều rộng và chiều cao này)
Chiều cao: 320
Khung hình: 30
Nhấn Generate. Đây là những gì tôi nhận được. Độ phân giải cao hơn và không còn dấu watermark trên video nữa!
Nâng cấp video bằng Zeroscope v2 XL
Bạn có thể làm cho video lớn hơn bằng cách thực hiện video-to-video. Điều này tương tự như hình ảnh-to-hình ảnh, trừ việc bây giờ bạn đang biến đổi một video thành một video khác.
Zeroscope v2 XL là một mô hình nâng cấp để phóng to video được tạo bởi mô hình Zeroscope v2 576.
Nhưng trước tiên, hãy cài đặt mô hình.
1. Tạo một thư mục mới stable-diffusion-webui > models > text2video > zeroscope_v2_XL
2. Bạn cần 4 tệp trong thư mục này. Hai tệp đầu tiên có thể được tìm thấy ở đây. Hai tệp còn lại có thể được tải xuống từ kho mô hình cơ bản của Modelscope. (Hoặc sao chép từ thư mục mô hình cơ bản)
open_clip_pytorch_model.bin
text2video_pytorch_model.pth
VQGAN_autoencoder.pth
configuration.json
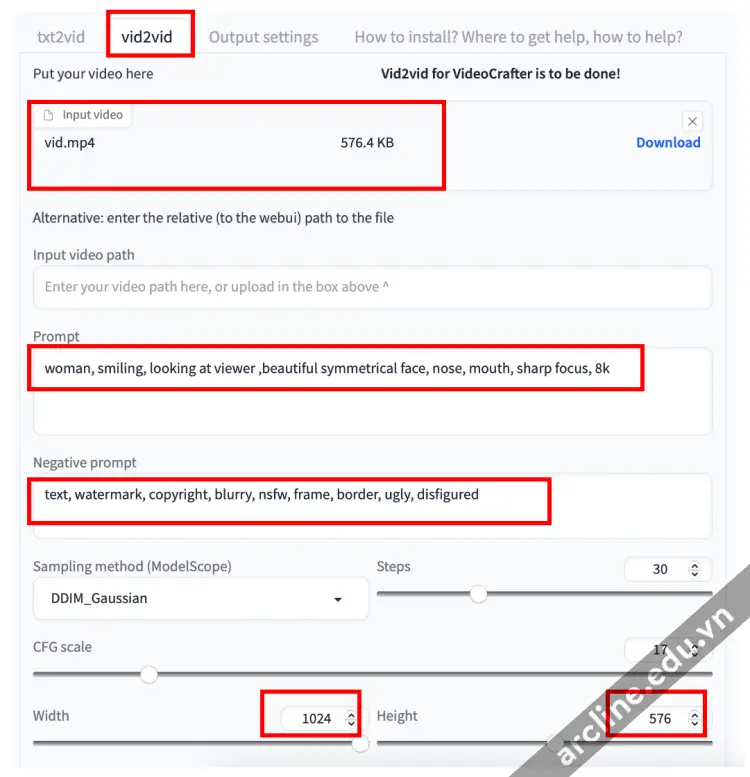
Để nâng cấp video bằng mô hình Zeroscope v2 XL, chuyển đến tab vid2vid.
Chọn mô hình: Zeroscope_v2_XL.
Tải lên video bạn đã tạo trước đó bằng Zeroscope v2 576w vào bảng Input video.
Nhập một gợi ý và một gợi ý phủ định. Bạn có thể tái sử dụng cùng một gợi ý.
Đặt chiều rộng là 1024 và chiều cao là 576. (QUAN TRỌNG: Bạn phải sử dụng các kích thước này)
Đặt Khung ảnh là 30.
Đặt độ mạnh làm mờ (denoising) là 0.7
Đặt khung bắt đầu vid2vid là 1. (Điều này giúp bảo tồn video gốc)
Nhấn Generate.
Đây là video chất lượng cao:
Mẹo
Giữ kích thước video 256×256 cho mô hình cơ bản. Các kích thước khác hoạt động không tốt. Tương tự, hãy giữ nguyên độ phân giải mặc định cho mô hình được điều chỉnh.
Như khi đặt câu hỏi cho các mô hình Stable Diffusion, hãy mô tả những gì bạn muốn THẤY trong video. Nhưng một số chủ đề đơn giản không hoạt động. Đừng quá quan tâm và chuyển sang từ khóa khác.
3. Deforum
Deforum tạo video bằng cách sử dụng các mô hình Stable Diffusion. Nó đạt được tính nhất quán của video thông qua img2img qua các khung ảnh. Vì đầu vào là nhiều gợi ý văn bản, nó đủ điều kiện để được gọi là một quy trình chuyển đổi từ văn bản sang video.